
이지은님의 블로그
250328 - Java Spring 플러스 프로젝트 쿼리 최적화: 인덱스를 이용하여 쿼리를 최적화 하기(explain, explain analyze) 본문
250328 - Java Spring 플러스 프로젝트 쿼리 최적화: 인덱스를 이용하여 쿼리를 최적화 하기(explain, explain analyze)
queenriwon3 2025. 3. 29. 04:45▷ 오늘 배운 것
인덱스를 설정하기 위해 프로젝트에 쿼리 최적화를 진행해보고자 한다.
<<목차>>
1. 어떤 쿼리를 최적화할 수 있을까?
1) UserRepository
2) RefreshTokenRepository
3) 그외 기타 등등...
4) ProductRepository
2. 인덱스를 설정하여 조회 성능 비교
1) 인덱스 설정 전
2) 인덱스 설정 후 성능 비교
1. 어떤 쿼리를 최적화할 수 있을까?
인덱스란 데이터의 저장(INSERT, UPDATE, DELETE) 의 성능을 희생하고 그 대신에 데이터의 읽기 속도를 높이는 테이블의 동작속도(조회)를 높여주는 자료구조이다.(https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%EC%9D%B8%EB%8D%B1%EC%8A%A4index-%ED%95%B5%EC%8B%AC-%EC%84%A4%EA%B3%84-%EC%82%AC%EC%9A%A9-%EB%AC%B8%EB%B2%95-%F0%9F%92%AF-%EC%B4%9D%EC%A0%95%EB%A6%AC)
그래서 프로젝트에서 검색 성능을 높이기 위해 인덱스를 사용한 조회 속도를 높여주려고 한다. 인덱스는 쓰기보다는 읽기가 많은 쿼리실행에 제일 많은 효율을 보여준다.
Repository하나씩 보며 인덱스사용이 효율적이고, 어떤 인덱스를 사용하면 좋을지를 살펴보자.
1) UserRepository
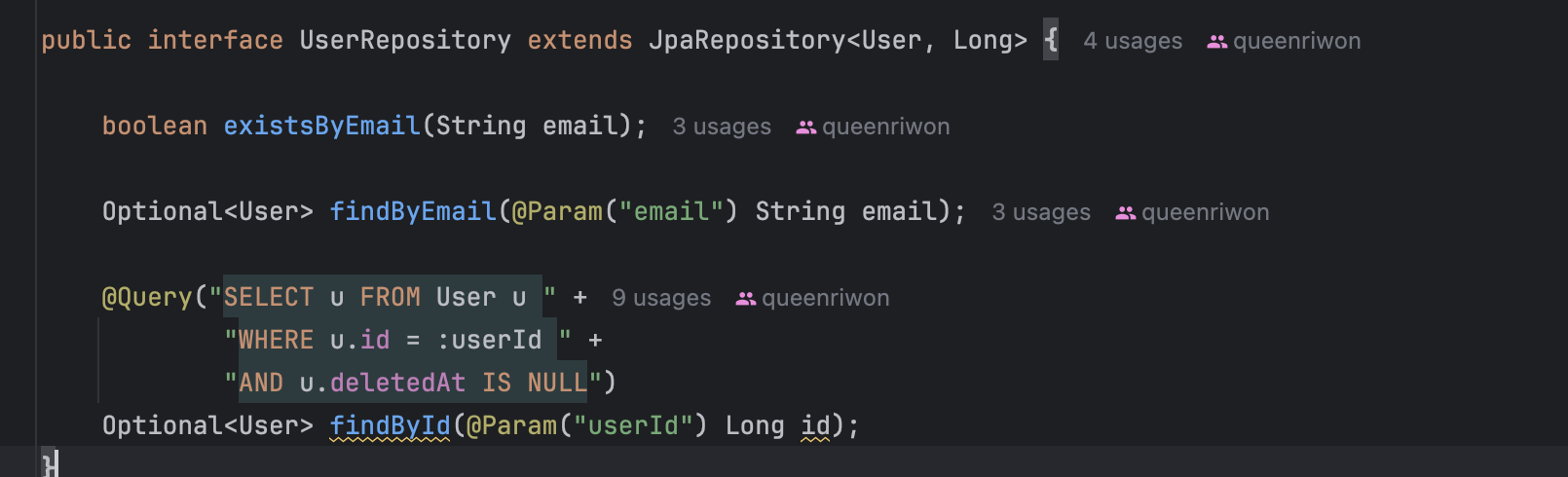
인덱스를 적용할 수 있는 필드는 email, id, deletedAt이다.
1️⃣ id: id는 기본키이기 때문에, 인덱스를 설정해주지 않아도 정렬이 되어 있다. 따라서 id의 대해 인덱스 설정을 해주지 않아도 된다.
2️⃣ email: email은 유니크로 지정되어 있다. 유니크의 경우 자동으로 인덱스설정 및 정렬이 되어있기 때문에 추가 설정을 해주지 않아도 된다.
3️⃣ deletedAt 또한 인덱스를 설정해줄 이유가 없는데, 조건문에서 null인지 아닌지만 필요하고, 보통 null인 값을 가져오기 때문이다.
따라서 User에는 성능 최적화를 하기위해 인덱스 설정이 필요 없다.
2) RefreshTokenRepository

인덱스를 적용할 수 있는 조건 필드는 token이다. 여기서 한가지 생각해봐야 할 사항이 있다. RefreshToken 테이블은 기본적으로 쓰기가 훨씬 많고, 읽기는 거의 없다. 따라서 인덱스는 INSERT를 할 때마다 재정렬을 하기 때문에 해당 테이블에 인덱스를 설정해주지 않아도 된다고 판단했다. 또한 token rotation 방식을 사용하지 않는다면 더더욱 설정해줄 필요가 없다.
3) 그외 기타 등등...
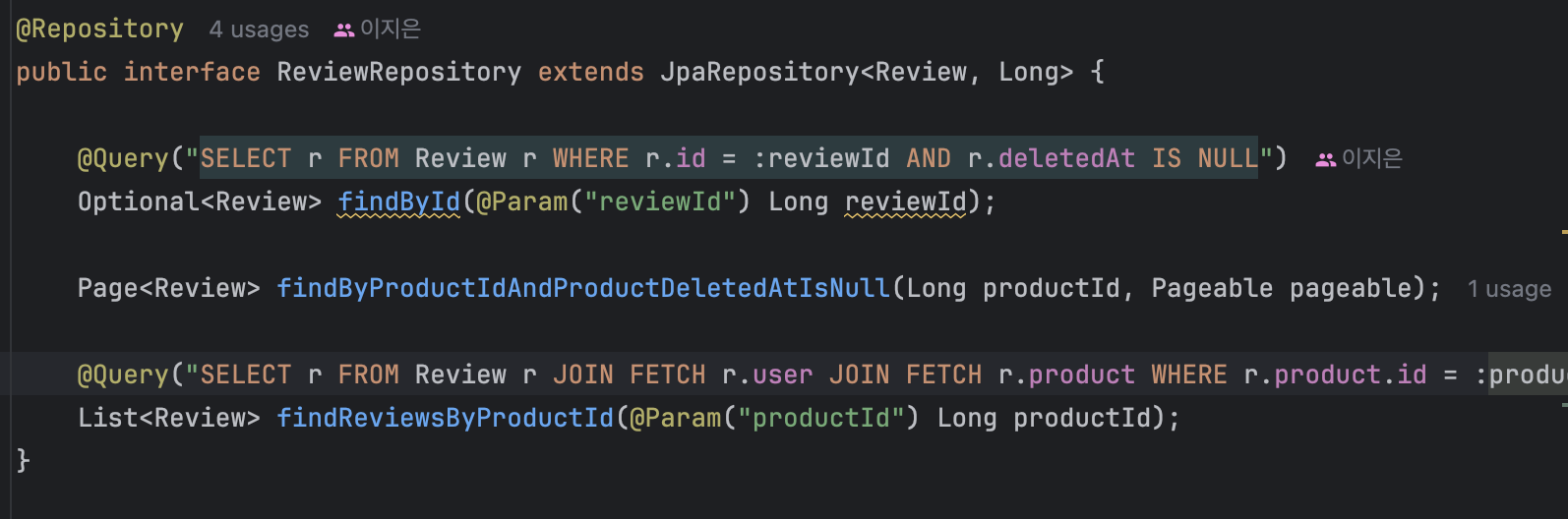

거의 모두 id, 기본키만 사용해서 데이터를 정렬해야할 이유가 없다.
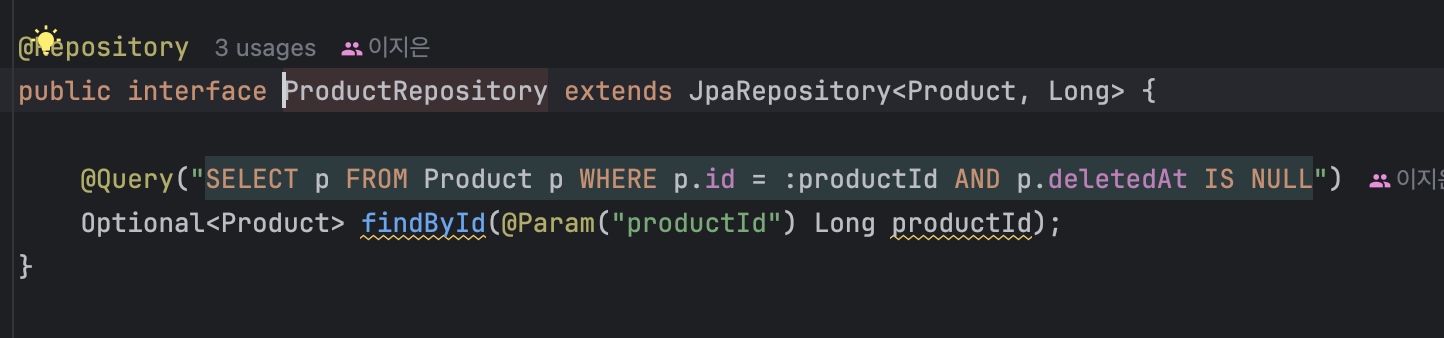
4) ProductRepository
@Query("SELECT new com.example.eightyage.domain.product.dto.response.ProductSearchResponseDto(p.name, p.category, p.price, AVG(r.score)) " +
"FROM Product p LEFT JOIN p.reviews r " +
"WHERE p.saleState = 'FOR_SALE' " +
"AND (:category IS NULL OR p.category = :category) " +
"AND (:name IS NULL OR p.name LIKE CONCAT('%', :name, '%')) " +
"GROUP BY p.name, p.category, p.price " +
"ORDER BY AVG(r.score)")
이 코드는 Product의 검색 조건으로 조회를 하는 코드이다 조건은 총 3가지인데, saleState, category, name이다. 이 세가지 칼럼을 적절히 조합하여 성능을 높일 수 있을 것 같다는 생각이 들었다.
2. 인덱스를 설정하여 조회 성능 비교
1) 인덱스 설정 전
성능 최적화 대상인 쿼리는 다음과 같다.
select
p1_0.name,
p1_0.category,
p1_0.price,
avg(r1_0.score)
from
product p1_0
join
review r1_0
on p1_0.id=r1_0.product_id
where
p1_0.sale_state='FOR_SALE'
and p1_0.category='MEN_CARE'
and p1_0.name like concat('%', 'ef54', '%') escape ''
group by
p1_0.name,
p1_0.category,
p1_0.price
order by
avg(r1_0.score)
limit
10
먼저 인덱스를 아무것도 지정해주지 않은 채 약 100~200만개의 제품 데이터, 500만개의 리뷰 더미데이터를 생성하고
postman으로 검색 결과를 확인하면 다음과 같다.(580ms)
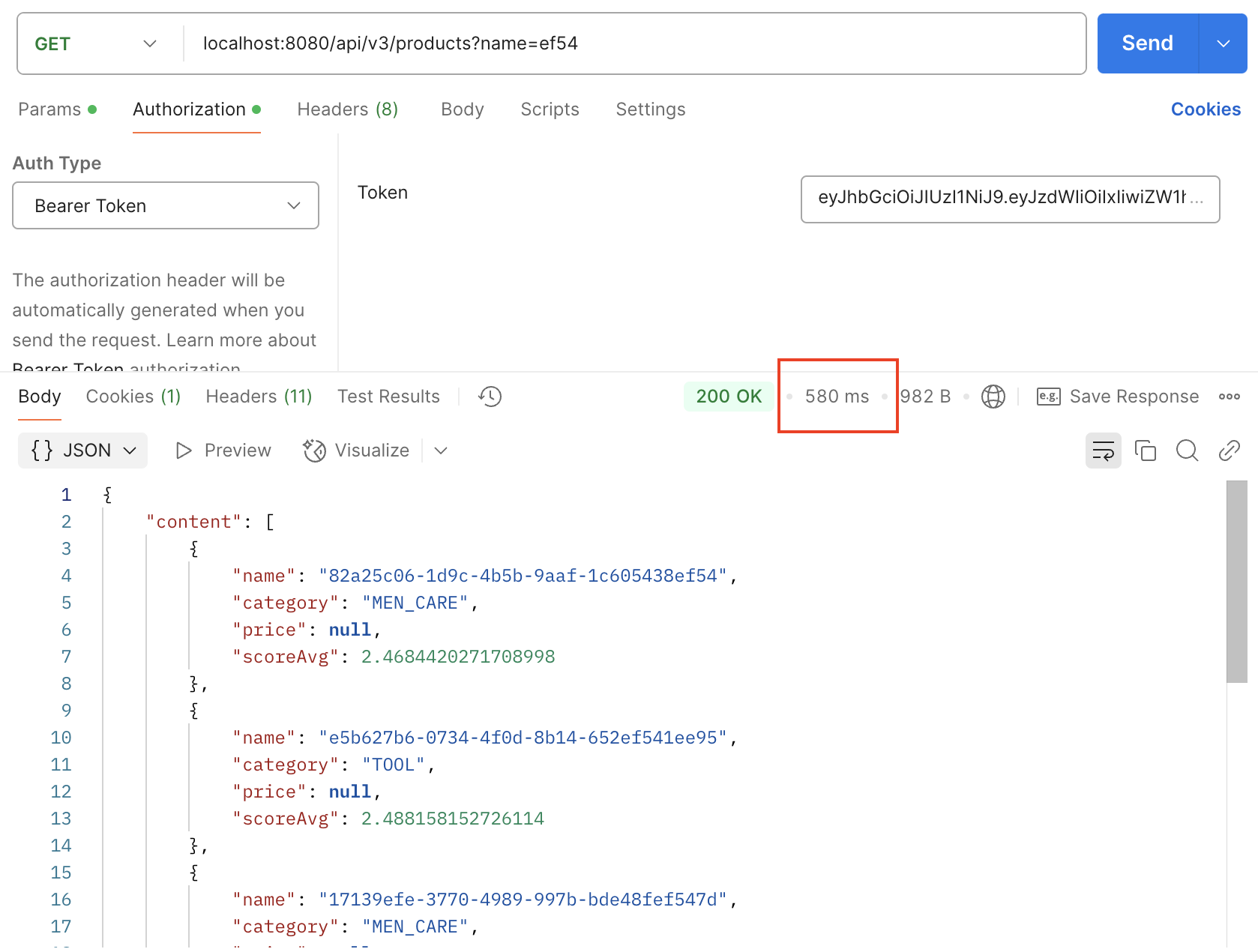
대용량의 데이터를 다루기 때문에 각 조건에 따라서 검색하고, like문에 대해서 검색하면 생각보다 시간이 오래 걸린다는 것을 확인 할 수 있다.
아래는 explain을 통해 쿼리 성능을 확인한 것이다.

간단히 해석해보자면 우리가 인덱스를 설정하고 싶은 product 테이블에 대한 쿼리를 실행시킬 때는 테이블 풀 테이블 스캔(type-ALL)을 사용하고, 아무 키도 사용하지 않았으며(key-null), 읽은 레코드의 수는 1019721개(rows-1019721)라는 것을 확인 할 수 있었다.
즉, 아무 인덱스도 사용하지 않기때문에 위 검색조건에 따른 정렬이 아무 것도 없다. 따라서 1019721개나 되는 상당한 양의 레코드를 스캔할 수 밖에 없었다. 이렇게 테이블의 레코드를 하나씩 스캔하는 것을 풀 테이블 스캔이라고 한다.
이는 상당히 느리게 동작하는 것이다. 그래서 적절한 인덱스를 설정해주어 성능을 향상시켜보자.
3개의 후보 인덱스가 있다. 하나씩 실행시켜보면서 어떤 인덱스가 최적화에 도움을 주는지 확인해보도록 하겠다.
1️⃣ idx-sale-state-category-name (saleState, category, name 순으로 설정)
2️⃣ idx-category-sale-state-name (category, saleState, name 순으로 설정)
3️⃣ idx-category-sale (category, saleState 순으로 설정)
2) 인덱스 설정 후 성능 비교
1️⃣ idx-sale-category-name (saleState, category, name 순으로 설정)
CREATE INDEX idx_category_sale_state_name
ON product (category, sale_state, name);다음과 같이 인덱스 설정을 하고(JPA에서는 @Table에서 가능) 더미데이터에 대한 응답을 확인하도록 하겠다. (70ms)
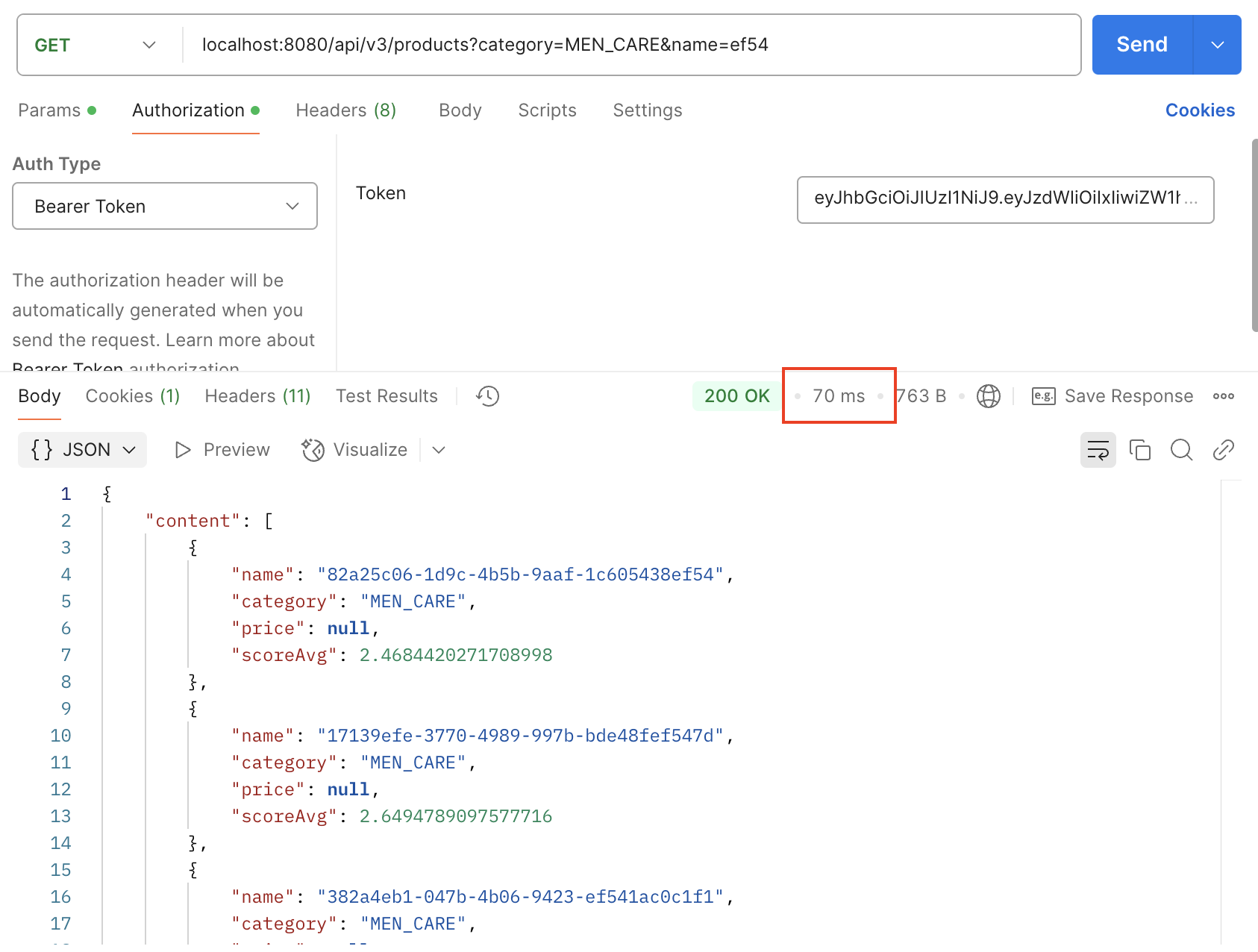
인덱스를 아무것도 설정안했을 때랑 비교하면 상당히 응답속도가 개선이 된 것을 확인 할 수 있다. (응답속도 8.29배 개선)
역시 explain을 통해 쿼리 성능을 확인해 보았다.

product 테이블에 대한 쿼리를 실행시킬 때는 인덱스를 활용한 스캔(type-ref)을 사용하고, ref 접근 방법이란 조인의 순서와 관계없을 때 + 제약조건이 없을때(유니크 등) + 인덱스의 종류와 관계 없이 사용되는 레코드 조회 방법이다.
idx-sale-state-category-name를 사용했으며, 읽은 레코드의 수는 145046개(rows-145046)라는 것을 확인 할 수 있었다.
그럼 인덱스를 적용하지 않았을때에 비해 얼마나 개선을까? (레코드 스캔 7.03배 개선)
확실히 인덱스 설정 전보다 응답속도가 개선이 되었다는 것을 알 수 있다.
explain analyze 명령어를 사용하여 실행계획을 확인해보자.
-> Limit: 10 row(s) (actual time=39.2..39.2 rows=3 loops=1)
-> Sort: avg(r1_0.score), limit input to 10 row(s) per chunk (actual time=39.2..39.2 rows=3 loops=1)
-> Table scan on <temporary> (actual time=39.2..39.2 rows=3 loops=1)
-> Aggregate using temporary table (actual time=39.2..39.2 rows=3 loops=1)
-> Nested loop inner join (cost=1.36e+6 rows=6.36e+6) (actual time=38.6..38.9 rows=126 loops=1)
-> Index lookup on p1_0 using idx_sale_state_category_name (sale_state = 'FOR_SALE', category = 'CLEANSING'), with index condition: ((p1_0.category = 'CLEANSING') and (p1_0.sale_state = 'FOR_SALE') and (p1_0.`name` like <cache>(concat('%','4d84','%')) escape '')) (cost=18690 rows=145046) (actual time=38.6..38.6 rows=3 loops=1)
-> Index lookup on r1_0 using FKiyof1sindb9qiqr9o8npj8klt (product_id = p1_0.id) (cost=43.6 rows=43.9) (actual time=0.0224..0.101 rows=42 loops=3)실제 실행시간 actual time=39.2..39.2 (39.2ms), 사용 비용 cost=1.36e+6 (1,360,000)이 사용 되었다는 것을 알 수 있다.
2️⃣ idx_category_sale_state_name (category, saleState, name 순으로 설정)
CREATE INDEX idx_category_sale_state_name
ON product (category, sale_state, name);인덱스를 재설정하고 postman응답 속도를 확인해보자. (120ms)

인덱스를 아무것도 설정안했을 때랑 비교하면 상당히 개선이 되었으나 1️⃣번 인덱스보다는 느리다는 것을 확인할 수 있다.(응답코드 4.83배)

1️⃣방법과 같은 스캔방법을 사용하고,
idx-category-sale-state-name를 사용했으며, 읽은 레코드의 수는 145846개(rows-145846)라는 것을 확인 할 수 있었다.
레코드 수로는 어느정도 개선되었을까? (레코드 스캔 6.99배 개선)
explain analyze 명령어를 사용하여 실행계획을 확인해보자.
-> Limit: 10 row(s) (actual time=51.6..51.6 rows=3 loops=1)
-> Sort: avg(r1_0.score), limit input to 10 row(s) per chunk (actual time=51.6..51.6 rows=3 loops=1)
-> Table scan on <temporary> (actual time=51.5..51.5 rows=3 loops=1)
-> Aggregate using temporary table (actual time=51.5..51.5 rows=3 loops=1)
-> Nested loop inner join (cost=1.36e+6 rows=6.36e+6) (actual time=43.6..51.3 rows=126 loops=1)
-> Index lookup on p1_0 using idx_category_sale_state_name (category = 'CLEANSING', sale_state = 'FOR_SALE'), with index condition: ((p1_0.sale_state = 'FOR_SALE') and (p1_0.category = 'CLEANSING') and (p1_0.`name` like <cache>(concat('%','4d84','%')) escape '')) (cost=20525 rows=145046) (actual time=42.9..42.9 rows=3 loops=1)
-> Index lookup on r1_0 using FKiyof1sindb9qiqr9o8npj8klt (product_id = p1_0.id) (cost=43.4 rows=43.9) (actual time=0.402..2.78 rows=42 loops=3)실제 실행 시간 actual time=51.6..51.6 (51.6ms), 비용은 cost=1.36e+6 (1,360,000)으로 1️⃣번 방법과 같은 비용이 소요되었다는 것을 확인할 수 있다.
3️⃣ idx_category_sale_state (category, saleState 순으로 설정)
CREATE INDEX idx_category_sale_state
ON product (category, sale_state);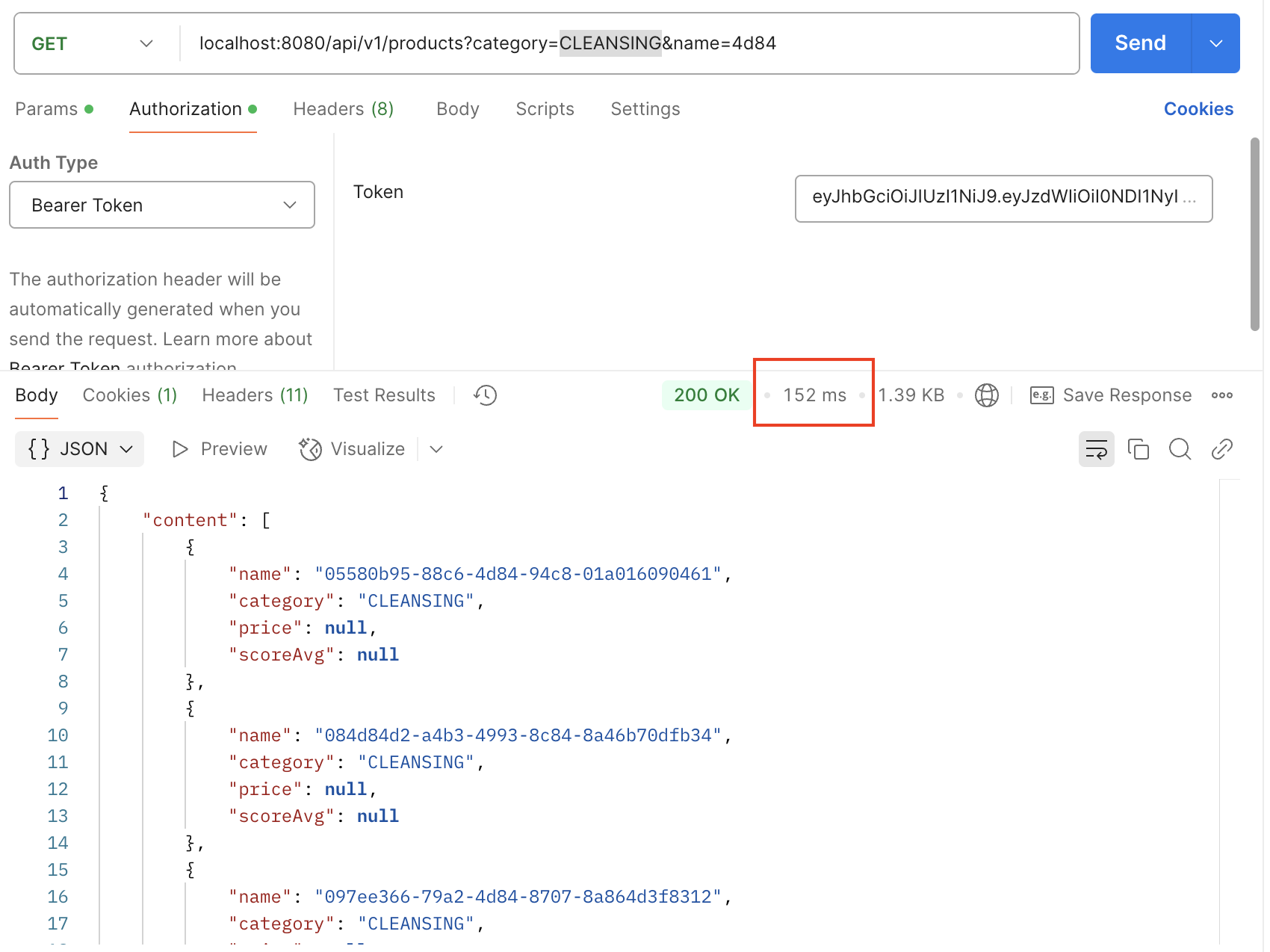
1️⃣과 2️⃣보다는 시간이 더 걸린 것을 확인할 수 있었다. (152ms, 응답속도 3.81배 효율)
explain table을 분석해보자.

같은 ref 스캔 방식에 키는 idx_category_sale_state, 스캔한 레코드의 수는 109560개라는 것을 확인할 수 있다.(레코드 수 9.31 효율)
1️⃣과 2️⃣보다는 레코드 수 스캔 관점에서 효율이 좋다는 것을 확인했다.
그러나 시간이 느린데, 스캔 효율성이 좋다는 것일까? 이를 확인해보기위해 explain analyze를 확인해보자.
-> Limit: 10 row(s) (actual time=122..122 rows=3 loops=1)
-> Sort: avg(r1_0.score), limit input to 10 row(s) per chunk (actual time=122..122 rows=3 loops=1)
-> Table scan on <temporary> (actual time=122..122 rows=3 loops=1)
-> Aggregate using temporary table (actual time=122..122 rows=3 loops=1)
-> Nested loop inner join (cost=619582 rows=556540) (actual time=2.37..121 rows=126 loops=1)
-> Filter: (p1_0.`name` like <cache>(concat('%','4d84','%')) escape '') (cost=10820 rows=12685) (actual time=2.22..113 rows=3 loops=1)
-> Index lookup on p1_0 using idx_category_sale_state (category = 'CLEANSING', sale_state = 'FOR_SALE'), with index condition: ((p1_0.sale_state = 'FOR_SALE') and (p1_0.category = 'CLEANSING')) (cost=10820 rows=114176) (actual time=0.31..105 rows=54853 loops=1)
-> Index lookup on r1_0 using FKiyof1sindb9qiqr9o8npj8klt (product_id = p1_0.id) (cost=43.6 rows=43.9) (actual time=0.0814..2.67 rows=42 loops=3)실제 시간은 actual time=122..122 (122ms), cost=619582 (619,582) 총 비용이 적다는 것을 확인 할 수 있다.
그러므로 이는 db에 들어가는 cost가 적은 대신 실행 시간이 조금 늦어진다는 것을 알 수 있다.
따라서 비용과 실행시간은 trade off라는 것을 확인할 수 있었다.
위 모든 경우를 인덱스가 없을때와 함께 비교분석을 해보자
| 인덱스 설정 없음 | 1️⃣ idx_sale_state_category_name | 2️⃣ idx_category_sale_state_name | 3️⃣ idx_category_sale_state | |
| postman 응답속도 | 580ms | 70ms(8.29배 개선) | 120ms(4.83배 개선) | 152ms(3.81배 개선) |
| 실제DB 실행시간 (actual time) |
39.2ms | 51.6ms | 122ms | |
| 레코드 스캔(rows) | 1019721개 | 145046개(7.03배 개선) | 145846개(6.99배 개선) | 109560개(9.31배 개선) |
| 비용(cost) | 1.36e+6 | 1.36e+6 | 619582 |
1️⃣ 실행계획이 가장 빠르고 3️⃣ 실행계획이 비용이 가장 낮다.
결론은 1️⃣ 실행 시간이 가장 짧고(39.2ms), 인덱스를 효율적으로 활용하여 불필요한 데이터 처리를 최소화했다는 것을 확인할 수 있었고, 비용 cost는 그만큼 크다는 것을 확인할 수 있었다.
성능이 가장 높은 것은 실행시간이 가장 짧은 idx_sale_state_category_name 인덱스가 가장 좋기 때문에 인덱스 설정을 다음과 같이 설정하도록 정했다.
@Table(name = "product",
indexes = @Index(name = "index_saleState_category_name", columnList = "saleState, category, name")
)

