
이지은님의 블로그
250327 - Java Spring JPA 인덱스를 이용한 성능개선 (데이터 100만건 삽입, 테스트 코드 작성하기, 인덱스로 검색 성능 개선하기) 본문
250327 - Java Spring JPA 인덱스를 이용한 성능개선 (데이터 100만건 삽입, 테스트 코드 작성하기, 인덱스로 검색 성능 개선하기)
queenriwon3 2025. 3. 27. 22:14▷ 오늘 배운 것
쿼리 성능 최적화를 위해 실습한 과제를 정리해보겠다.
<<목차>>
1. 데이터 100만건 넣기
1) 데이터 삽입하는 jdbc 클래스 만들기
2) 테스트 코드 작성하기
2. 인덱스를 이용한 성능개선
1. 데이터 100만건 넣기
JdbcTemplate을 활용하면 JPA보다 더 직접적인 SQL 실행을 할 수 있기 때문에 많은 데이터를 넣어 부하테스트를 하기 위해서는 JDBC를 사용해야한다.
JPA의 경우 영속성 컨텍스트를 관리하며 객체를 매핑하는 과정이 있기 때문에, 대량 데이터를 다룰 때 불필요한 메모리 사용이 발생할 수 있다.
1) 데이터 삽입하는 jdbc 클래스 만들기
@Repository
@RequiredArgsConstructor
public class UserBulkRepository {
private final JdbcTemplate jdbcTemplate;
private final int BATCH_SIZE = 1000;
public void bulkInsertUsers(List<User> users) {
String sql = "INSERT INTO users (email,password,nickname) values (?, ?, ?)";
jdbcTemplate.batchUpdate(sql, users, BATCH_SIZE, (ps, argument) -> {
ps.setString(1, argument.getEmail());
ps.setString(2, argument.getPassword());
ps.setString(3, argument.getNickname());
});
}
}쿼리를 batch_size에 맞게 삽입하기 위해서 jdbcTemplate.batchUpdate()를 사용한다.
한번의 쿼리문을 날리게 되면 데이터 베이스에 과부화가 올 수 있으니 메모리 사용 최적화를 위해 배치 사이즐르 지정한다.
(ps, argument) -> {...} 람다 표현식의 경우
ps는 PreparedStatement 객체(SQL 쿼리에 값을 넣는 역할), argument는 처리중인 User를 뜻한다. 이후 ? 하나씩 값을 바인딩 해준다.
2) 테스트 코드 작성하기
@SpringBootTest
@ActiveProfiles("test")
@Import({JwtUtil.class})
class ExpertApplicationTests {
@Autowired
private UserBulkRepository userBulkRepository;
@Test
void 유저_데이터_백만건_생성() {
List<User> batchList = new ArrayList<>();
for (int i = 0; i < 1_000_000; i++) {
User user = new User(i + "@email.com", "name" + i, "password", UserRole.ROLE_USER);
batchList.add(user);
if (batchList.size() == 1000) {
userBulkRepository.bulkInsertUsers(batchList);
batchList.clear();
sleep(500);
}
}
if (!batchList.isEmpty()) {
userBulkRepository.bulkInsertUsers(batchList);
batchList.clear();
}
}
private static void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}다음과 같이 batchlist를 저장하여 위에서 작성한 메서드에 전송한다. 너무 많은 양을 단기간에 한번에 담으면 과부화가 걸릴 수 있으므로 한번 1000건마다 0.5초씩 쉬어준다
이 테스트를 실행하면 약 9분의 시간이 걸려 다음과 같이 백만건의 유저 데이터를 저장할 수 있다.

2. 인덱스를 이용한 성능개선
많은 데이터 사이에서 특정 유저를 찾을 때 얼마의 시간이 걸릴까?
제일 마지막에 추가된 유저의 이메일을 조회해보자
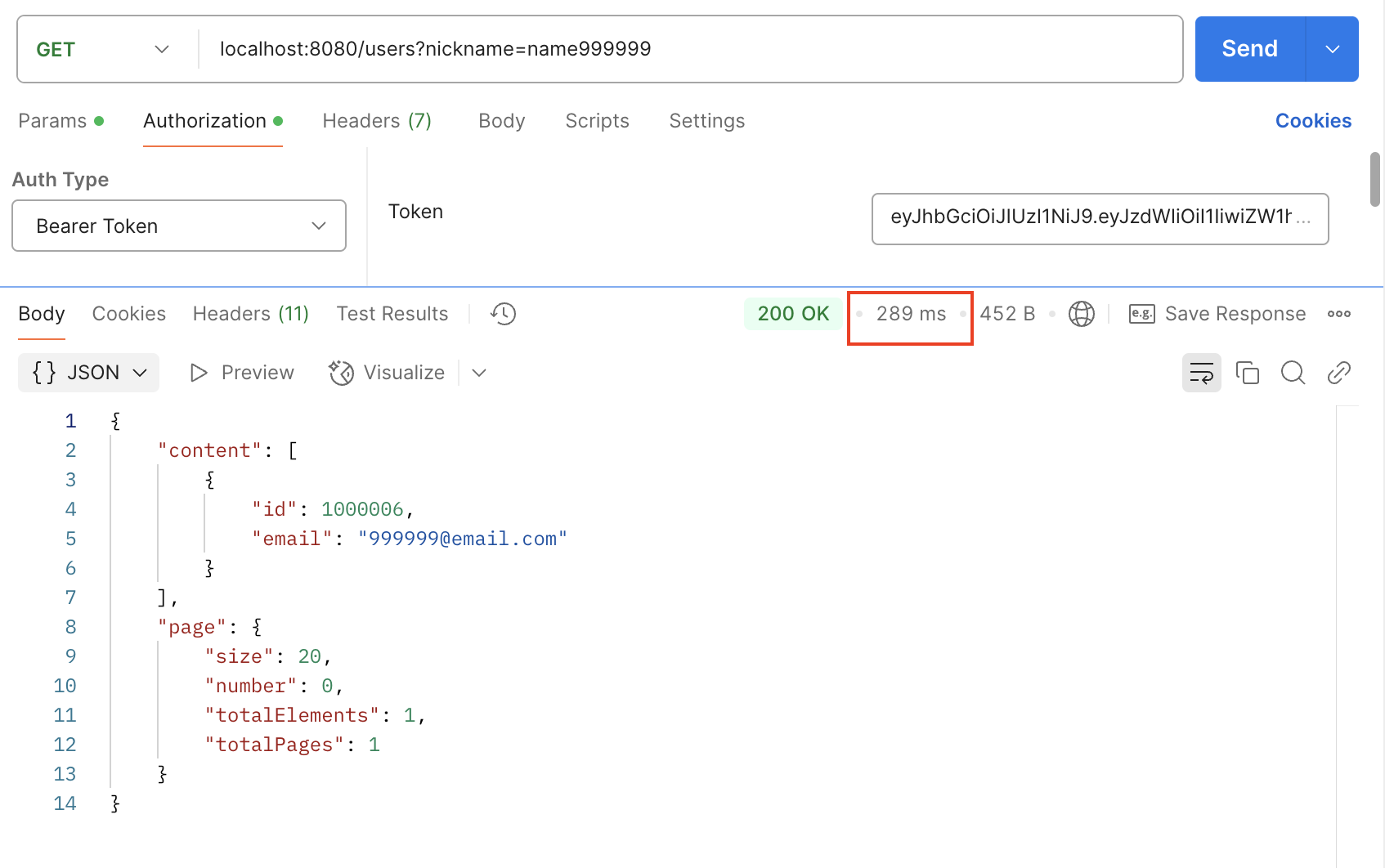
explain SELECT * FROM users
WHERE nickname = 'name999999';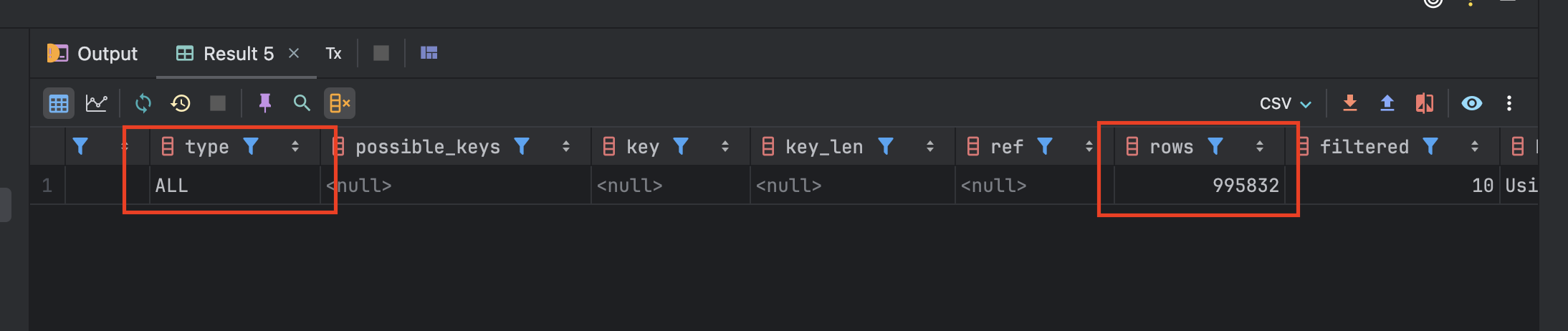
모든 테이블을 검색하는 방법(type)으로 995852번 레코드를 탐색한 결과 마지막 999999@email.com을 조회할 수 있었다.
이것을 postman 응답으로 출력해보면 289ms가 걸렸다는 것을 확인할 수 있다.
그럼 테이블의 값을 검색할때 더 빠르게 검색하기 위해서는 어떤 방법을 사용해야할까. 제일 빠르고 확실한 것은 인덱스이다.
인덱스를 활용하면 해당 칼럼을 기준으로 정렬을 먼저 시켜준다.(B-Tree인덱스 사용)
인덱스 설정을 엔티티에 설정해주도록 하자.
@Getter
@Entity
@NoArgsConstructor
@Table(
name = "users",
indexes = @Index(name = "idx_email", columnList = "email"))
public class User extends Timestamped {...}
Email대해 인덱스를 설정해준다.
이후 실행및 쿼리를 실행시켜서 얼마나 실행속도가 개선되었는지 확인해보자.
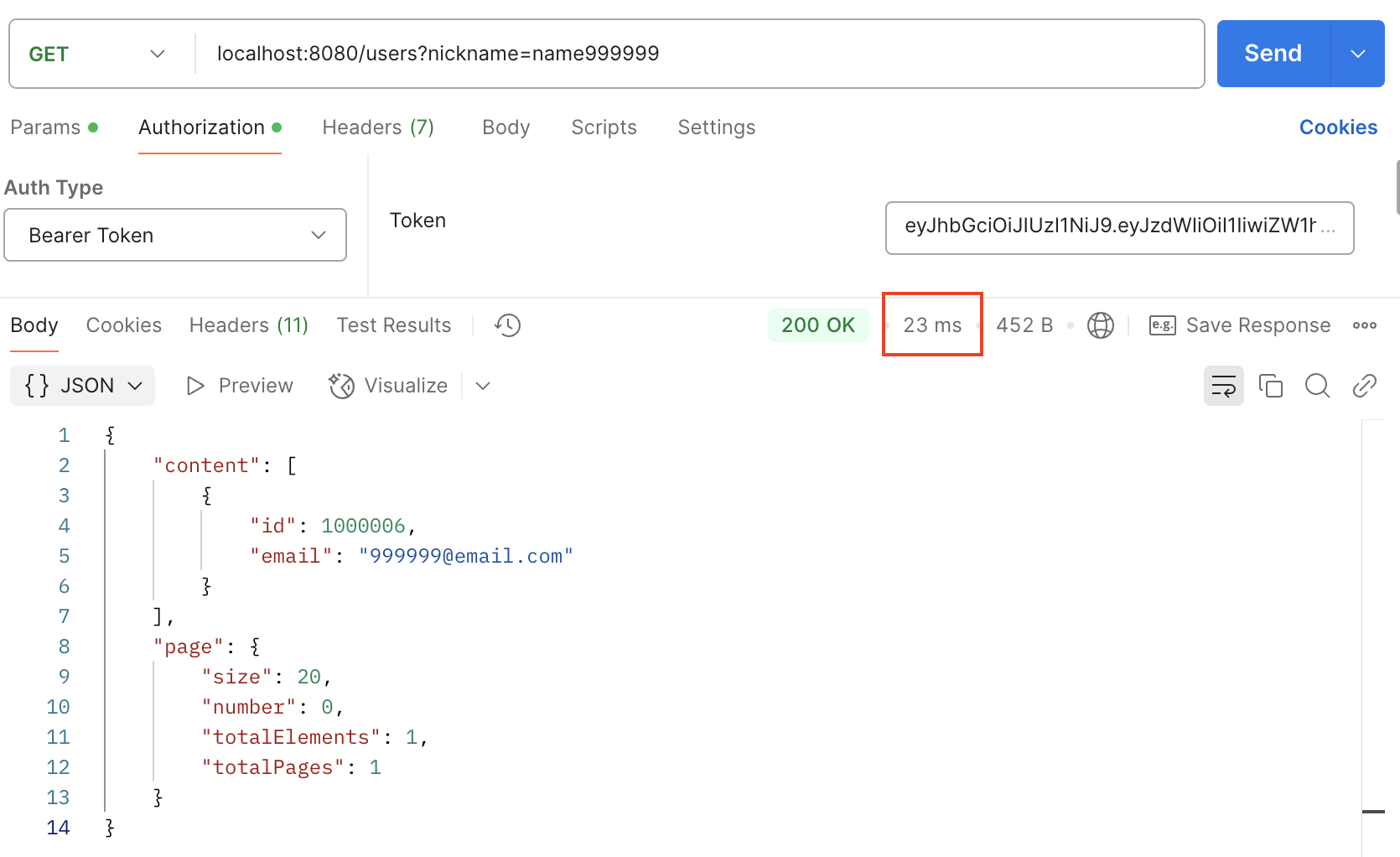
explain SELECT * FROM users
WHERE nickname = 'name999999';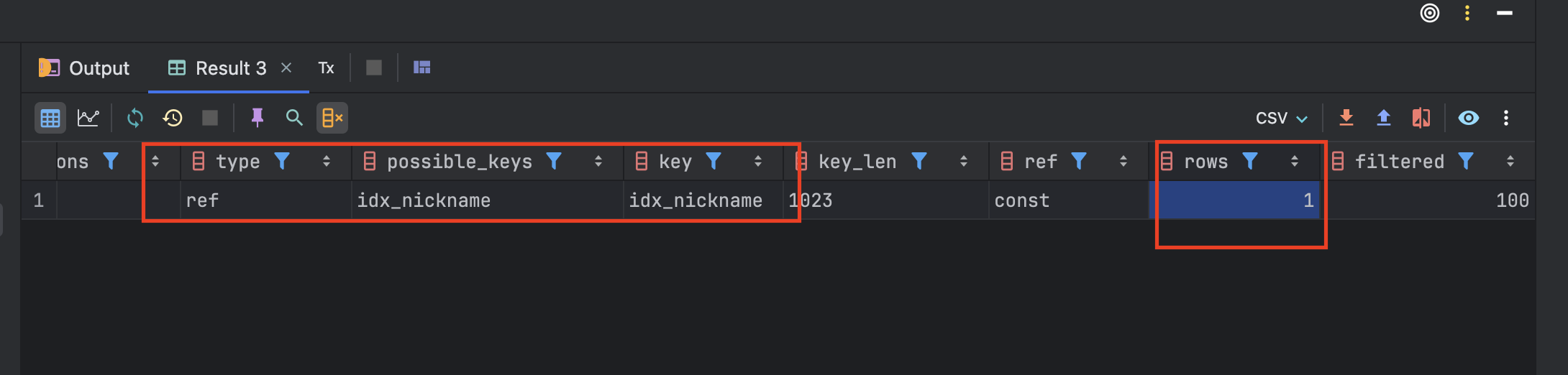
인덱스 설정후로는 응답이 23ms 가 걸린다는 것을 확인할 수 있었다. 쿼리 실행도 부분 인덱스 검색(ref)을 사용하여 레코드를 한번에 조회할 수 있었다.
289ms -> 23ms, 즉 거의 90%가 개선되었다는 것을 확인할 수 있었다.
인덱스를 통해 검색 쿼리의 성능을 증가시킬 수 있다는 것을 확인할 수 있다.
▷ 참고한 블로그
https://passionfruit200.tistory.com/750
[Spring Boot][Seminar-hub] 데이터 100만건 1초만에 삽입하기 with jdbcTemplate.batchUpdate()
대규모 데이터를 가지고서 SQL을 활용하여 데이터의 성능을 확인해보고자 할떄, 테스트를 위한 대규모의 데이터들이 필요합니다. JPA Hibernate 가 Save / SaveAll 에서 JdbcTemplate의 Hibernate가 비활성화된
passionfruit200.tistory.com
[JPA] DB Index 개념과 JPA에서 Index 설정하기
스터디에서 DB Index와 관련된 테코톡을 다 같이 시청했는데 JPA에서는 어떻게 적용하는지가 궁금해졌습니다.Index 우하한 테코톡 영상인덱스의 개념을 알아보고 JPA로 어떻게 인덱스를 사용하는지
velog.io

