

이지은님의 블로그
250225 - Java Spring 심화: Bean 생명주기, JPQL, N+1문제(@Query, @Param, join fetch, @BatchSize) 본문
250225 - Java Spring 심화: Bean 생명주기, JPQL, N+1문제(@Query, @Param, join fetch, @BatchSize)
queenriwon3 2025. 2. 25. 16:39▷ 오늘 배운 것
Java Spring 심화 강의를 듣고 배우고 정리한 것을 블로그로 작성해보도록 하겠다.
<<목차>>
1. Bean 생명주기
1) Bean 생성주기 과정
2) Spring 생명주기 콜백 방법
3) Bean Scope
2. JPQL
1) JPQL 특징
2) JPQL 문법 규칙
3) 반환타입
4) 결과 조회
5) @Embedded
6) 프로젝션
7) Paging
3. Fetch join
1) N+1 문제
2) Entity fetch join
3) Collection fetch join
4) @BatchSize
4. 프로필 설정
1. Bean 생명주기
: spring은 Bean의 생성과 관리, 소멸까지 자동처리
1) Bean 생성주기 과정
1️⃣ Spring Container 생성

애플리케이션 실행되면 ApplicationContext, BeanFactory 컨테이너 생성, @Configuration, @ComponentScan, XML 등으로 Bean 정의 정보읽음
2️⃣ Bean 인스턴스 생성

기본 생성자가 호출되어 객체를 생성한다.(기본 싱글톤 Bean)
- 싱글톤 Bean: 애플리케이션이 시작할 때 미리 생성
- 프로토타입 Bean: 실행시점이 아닌 요청이 들어오면 생성
3️⃣ 의존성 주입(DI)
Spring은 지정된 의존성 주입을 생성자 주입으로 사용한다.
4️⃣ 초기화 콜백(콜백 메서드 작업)
초기화 작업(해당 Bean이 사용될 준비를 마치는 과정): 데이터베이스 연결, 리소스 준비, 설정작업 등
@PostConstruct, InitializingBean - afterPropertiesSet() 메서드 호출
5️⃣ Bean 사용
의존성 주입 후 자유로운 Bean 사용
6️⃣ 소멸 전 콜백
애플리케이션 또는 컨테이너 종료: 파일 닫기, 데이터베이스 연결 해제 등 리소스 정리
7️⃣ Spring 종료
Spring Bean을 메모리에서 제거
2) Spring 생명주기 콜백 방법
1️⃣ InitalizingBean, DisposableBean Interface
2️⃣ @Bean 속성
3️⃣ @PostConstruct, @PreDestroy Annotation
1️⃣ InitalizingBean, DisposableBean Interface
public class MyBean implements InitializingBean, DisposableBean {
...
// InitializingBean 인터페이스의 초기화 메서드
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("MyBean 초기화 - afterPropertiesSet() 호출됨");
System.out.println("data = " + data);
}
// DisposableBean 인터페이스의 종료 메서드
@Override
public void destroy() throws Exception {
System.out.println("MyBean 종료 - destroy() 호출됨");
data = null;
}
...
}=> Spring에 의존적이기 때문에, 외부 라이브러리 등의 코드에 적용할 수 없다. Method의 이름을 바꿀 수 없다.(오버라이딩)
2️⃣ @Bean 속성
// MyBeanV2 클래스
public class MyBeanV2 {
...
public void init() {
System.out.println("MyBean 초기화 - init() 호출됨");
System.out.println("data = " + data);
}
public void close() {
System.out.println("MyBean 종료 - close() 호출됨");
data = null;
}
...
}
// AppConfigV2 클래스
@Configuration
public class AppConfigV2 {
@Bean(initMethod = "init", destroyMethod = "close")
public MyBeanV2 myBeanV2() {
MyBeanV2 myBeanV2 = new MyBeanV2();
// 의존관계 설정
myBeanV2.setData("Example");
return myBeanV2;
}
}=> Bean이 Spring 내부적으로 구현된 코드에 의존하지 않는다. 메서드 이름을 자유롭게 설정할 수 있다.
=> 외부 라이브러리에도 초기화, 종료 메서드를 적용할 수 있다.
3️⃣ @PostConstruct, @PreDestroy
- @PostConstruct(초기화): Bean이 생성되고 의존성 주입이 완료된 후에 호출되는 메서드를 지정한다.
- @PreDestroy(리소스 정리): Bean이 소멸되기 직전에 호출되는 메서드를 지정한다.
public class MyBeanV3 {
...
// 초기화 메서드
@PostConstruct
public void init() {
System.out.println("MyBean 초기화 - init() 호출됨");
System.out.println("data = " + data);
}
// 소멸 메서드
@PreDestroy
public void destroy() throws Exception {
System.out.println("MyBean 종료 - destroy() 호출됨");
data = null;
}
...
}=> 외부 라이브러리에 적용이 불가능하다.
3) Bean Scope
: Spring 컨테이너에서 Bean이 어떻게 생성되고 관리되는지를 정의하는 개념으로 Spring은 다양한 범위(스코프)를 제공하여 Bean의 생명주기를 설정할 수 있는데, 각 스코프는 Bean이 얼마나 오래 유지되는지, 여러 번 사용할 수 있는지 등을 결정한다.
1️⃣ 싱글톤(Singleton)

: Spring 컨테이너 내에서 Bean이 하나만 생성되고 모든 요청이 같은 객체를 사용한다.
주소값이 같은 인스턴스 공유(같은 Bean 객체 조회), 초기화, 종료 메서드 정상 실행
2️⃣ 프로토타입(prototype)

: 요청할 때마다 새로운 인스턴스가 생성된다. 필요한 의존관계를 주입한다.
생성한 프로토타입 Bean을 클라이언트에게 반환한다.
컨테이너는 프로토타입 Bean의 생성, 의존관계 주입, 초기화 까지만 수행한다. 그 이후 생명주기(소멸, @PreDestroy)는 관리하지 않는다.
조회할 때 Bean이 생성되고 초기화, close가 되어도 소멸하지 않는다.
3️⃣ 웹 스코프
request
- HTTP 요청마다 새로운 Bean 이 생성된다.
- 웹 요청이 들어오면 Bean 생성되고 요청이 완료되면 소멸된다.
- Spring MVC로 만든 Web Application에서 사용하는 방식
session
- HTTP 세션 동안 하나의 Bean 인스턴스를 유지한다.
- 웹 세션이 시작되면 생성되고 종료될 때 소멸한다.
application
- 서블릿 컨텍스트 내에서 Bean이 단일 인스턴스로 존재한다.
- 애플리케이션이 구동되는 동안 동일한 객체가 유지된다.
// 자동 등록
@Scope("singleton") // 생략 가능(기본 값)
@Component // @Service 사용 가능
public class MemberServiceImpl implements MemberService { ... }
// 수동 등록
@Configuration
public class AppConfig {
@Scope("singleton") // 생략 가능
@Bean
public MemberService memberService() {
return new MemberServiceImpl();
}
}
// singleton 스코프 사용
@Configuration
public class SingletonAppConfig {
@Scope("singleton")
@Bean
public SingletonBean singletonBean() {
SingletonBean singletonBean = new SingletonBean();
return singletonBean;
}
}
// prototype 스코프 사용
@Configuration
public class ProtoTypeAppConfig {
@Scope("prototype")
@Bean
public ProtoTypeBean protoTypeBean() {
ProtoTypeBean protoTypeBean = new ProtoTypeBean();
return protoTypeBean;
}
}
| Singleton(Default) | Prototype | Request | |
| 특징 | - 대부분의 Sevice, Repository 등 Application 전체에서 공유되는 Bean - 상태를 가지면 안된다. |
- 매번 새로운 인스턴스가 필요한 경우 - 상태를 가지는 객체(특정 설정값이 다른 임시 작업 객체) |
- Web Application에서 요청별로 별도의 Bean이 필요한 경우 - 요청 데이터를 처리하는 객체 |
2. JPQL
JPA의 SQL Query 지원
1️⃣ JPQL(Java Persistence Query Language)
- 객체지향 쿼리 언어
- Entity 객체를 대상으로 SQL Query를 작성할 수 있도록 도와준다.
2️⃣ QueryDSL
- Java 기반의 ORM 쿼리 빌더 라이브러리
- 동적 쿼리를 지원한다.
3️⃣ JPA Criteria
- JPQL과 유사한 쿼리를 코드로 생성할 수 있다.
- 복잡하고 실용성이 없어서 QueryDSL을 사용한다.
4️⃣ Native SQL
- JPA가 제공하는 SQL을 직접 사용하는 기능
- 표준 SQL이 아닌 Database 종속적인 Query가 필요할 때 주로 사용
1) JPQL 특징
- 객체를 대상으로 검색하는 객체 지향 쿼리(테이블 X)
- SQL 추상화(DB 종속 X): 다양한 데이터베이스에서 사용이 가능하다.
- JPA의 영속성 컨텍스트를 사용하여 1차 캐시, 지연 로딩 등의 기능을 활용할 수 있다.
- 타입 안정성
| 특징 | JPQL | SQL |
| 대상 | Entity와 필드 | 테이블과 컬럼 |
| 표현 방식 | 객체지향 | 관계형 |
| DB 독립성 | 높음 | 특정 DB 종속 |
| 호출 방식 | EntityManager.createQuery() | 직접 DB와 연결 |
2) JPQL 문법 규칙
- 테이블 이름이 아닌 Entity 이름을 사용한다.(클래스 이름이 Default)
- Entity와 필드는 대소문자를 구분한다.
- JPQL 키워드(SELECT, from, Where)는 대소문자를 구분하지 않는다.
- 별칭(alias)은 필수이고 as 는 생략이 가능하다.
SELECT <별칭> FROM <엔티티 이름> [AS <별칭>] [WHERE 조건] [GROUP BY 속성] [HAVING 조건] [ORDER BY 속성]
3) 반환타입
1️⃣ TypeQuery
- 반환 타입이 명확할 때 사용한다.
- 컴파일 시 타입 검사를 할 수 있다.
TypedQuery<Tutor> typeQuery1 = em.createQuery("select t from Tutor t", Tutor.class);
TypedQuery<String> typeQuery2 = em.createQuery("select t.name from Tutor t", String.class);
2️⃣ Query
- 반환타입이 명확하지 않을 때 사용
- 결과를 처리할 때 형변환 필요
Query query = em.createQuery("select t.name, t.age from Tutor t");
3️⃣ 파라미터 바인딩
: 파라미터 바인딩은 동적으로 값을 전달하여 SQL 인적션 방지
Tutor wonuk = em.createQuery("select t from Tutor t where t.name = :name", Tutor.class)
.setParameter("name", "wonuk")
.getSingleResult();
System.out.println("wonuk.getName() = " + wonuk.getName());
System.out.println("wonuk.getAge() = " + wonuk.getAge());
4) 결과 조회
1️⃣ getResultList()
: 결과가 하나 이상일 때, 결과가 없다면 빈 List 반환
List resultList = em.createQuery("select t from Tutor t").getResultList();
2️⃣ getSingleResult()
: 결과가 딱 하나일 때 결과가 없거나 여러개라면 예외 발생(NoResultException, NonUniqueResultException)
Tutor singleResult = em.createQuery("select t from Tutor t where t.id = 1L", Tutor.class).getSingleResult();
5) @Embedded
@Embedded
private Period workPeriod;
// Embedded 정의
@Embeddable public class Period {
@Temporal(TemporalType.DATE)
Date startDate;
@Temporal(TemporalType.Date)
Date endDate;
public boolean isWork (Date date) {
// startDate <= date <= endDate 확인
return (startDate == null || !date.before(startDate)) && (endDate == null || !date.after(endDate));
}
}- 하나의 임베디드 타입으로 정의하여 여러 Entity에서 재사용 가능
- 응집도 증가 → 단일 책임 원칙 준수
- 독립적인 로직 작성 가능
6) 프로젝션
: entity 전체가 아닌 특정 필드만 선택하여 조회하는 방식. 필요한 데이터만 조회하여 성능을 최적화하여 네트워크 비용을 줄일 수 있다.
- DISTINCT 중복 제거가 가능하다.
- Entity 프로젝션을 사용하면 영속성 컨텍스트가 관리한다.
- 연관된 Entity를 JOIN하여 조회할 수 있다
사용예시
SELECT t FROM Tutor t // Entity
SELECT t.company FROM Tutor t // Entity
SELECT t.period // Embedded
SELECT t.name, t.age FROM Tutor t // Scala
SELECT DISTINCT t.name, t.age FROM Tutor t // 중복 제거
// 1. 묵시적 조인 -> 예측하기 어려움
Company company = em.createQuery("select t.company from Tutor t", Company.class).getSingleResult();
// 2. 명시적 조인 -> 주로 사용
companyV2 = em.createQuery("select t from Tutor t join t.company", Company.class).getSingleResult();
1️⃣ 임베디드 프로젝션
em.createQuery("select t.period from Tutor t", Period.class).getResultList();- select period from Period p 는 불가능하다.
- 임베디드를 사용할 때, select t from Tutor t where t.period.startDate < ?
- 상속(@MappedSuperclass)을 사용할때, select t from Tutor t where t.startDate < ? -> 편리하고 직관적
2️⃣ 스칼라 프로젝션
// 1. 형변환 사용
List resultList = em.createQuery("select t.name, t.age from Tutor t").getResultList();
Object o = resultList.get(0);
Object[] result = (Object[]) o;
System.out.println("result[0] = " + result[0]);
System.out.println("result[1] = " + result[1]);
// 2. List<object[]>로 반환
List<Object[]> resultList = em.createQuery("select t.name, t.age from Tutor t").getResultList();
Object[] result = resultList.get(0);
System.out.println("result[0] = " + result[0]);
System.out.println("result[1] = " + result[1]);Scala 프로젝션은 DTO 형태로 반환받을 수 있다.
7) Paging
- setFirstResult(int startPosition): 조회 시작 위치
- setMaxResult(int maxResult): 조회할 데이터 수
3. Fetch join
: JPA가 연관된 엔티티를 조회할 때 추가적인 쿼리를 반복적으로 실행하기 때문에 발생하는 문제
1) N+1 문제
N+1 문제는 지연로딩, 즉시로딩 모두에서 발생한다.
지연로딩의 Tutor와 Campany의 N:1 양방향 연관관계
String query = "select t from Tutor t";
List<Tutor> tutorList = em.createQuery(query, Tutor.class).getResultList();
for (Tutor tutor : tutorList) {
System.out.println("tutor.getName() = " + tutor.getName());
System.out.println("tutor.getCompany().getName() = " + tutor.getCompany().getName()); // 지연로딩 발생
}
Tutor에 3개의 데이터가 있을때, 4개의 쿼리가 실행되나
첫번째와 세번째 tutor의 company값이 같다(1차 캐시 저장)
Tutor 3은 쿼리를 실행하지 않음
=> 해결 방법: 1️⃣ fetch join 2️⃣ @BatchSize
2) Entity fetch join
: JPQL에서 성능 최적화를 위해 fetch join을 제공하며 연관된 엔티티나 컬렉션을 SQL 한번으로 조회할 수 있도록 해주는 기능
- 일반 JOIN

- Fetch join

=> 튜터를 조회할 때 연관된 회사도 함께 조회한다.
관련된 데이터를 전부 조회하여 반복적인 쿼리실행이 필요하지 않도록 한다.
String query = "select t from Tutor t join fetch t.company";
지연로딩을 설정해도 fetch join이 우선권을 가진다.
Fetch join 후 모든 엔티티가 영속성 컨텍스트로 관리된다.(프록시가 아닌 진짜 겍체조회)
3) Collection fetch join
String query = "select c from Company c join fetch c.tutorList";
List<Company> companyList = em.createQuery(query, Company.class).getResultList();
for (Company company : companyList) {
System.out.println("company.getName() = " + company.getName());
System.out.println("company.getTutorList().size() = " + company.getTutorList().size());
}

튜터리스트에 대해서 함께 조회한다.

단 해당 SQL 쿼리의 조회결과는 데이터가 중복된다.
- Hibernate 6.0 이상은 DISTINCTION 가 자동으로 적용된다.
- Hibernate 6.0 이하는 DISTINCTION가 조회되지 않는다. (JPQL의 DISTINCTION는 같은 PK값을 가진 엔티티를 제거한다.)
Collection에 fetch join을 사용하면 페이징을 메모리에서 수행
-> 전체를 조회하는 SQL가 실행되면, 페이징 반영이 되지 않는다.
-> 필요없는 데이터까지 로드 후 필터링한다.
4) @BatchSize
JPA에서 N+1문제를 해결하기 위해 사용되는 설정
지연로딩시 한번에 로드할 엔티티의 개수를 조정하여 여러개의 엔티티를 효율적으로 조회할 수 있다.
// 1. @BatchSize 적용 전
String query = "select c from Company c";
List<Company> companyList = em.createQuery(query, Company.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList();
System.out.println("companyList.size() = " + companyList.size());
for (Company company : companyList) {
System.out.println("company.getName() = " + company.getName());
for (Tutor tutor : company.getTutorList()) {
System.out.println("tutor.getName(): " + tutor.getName());
}
}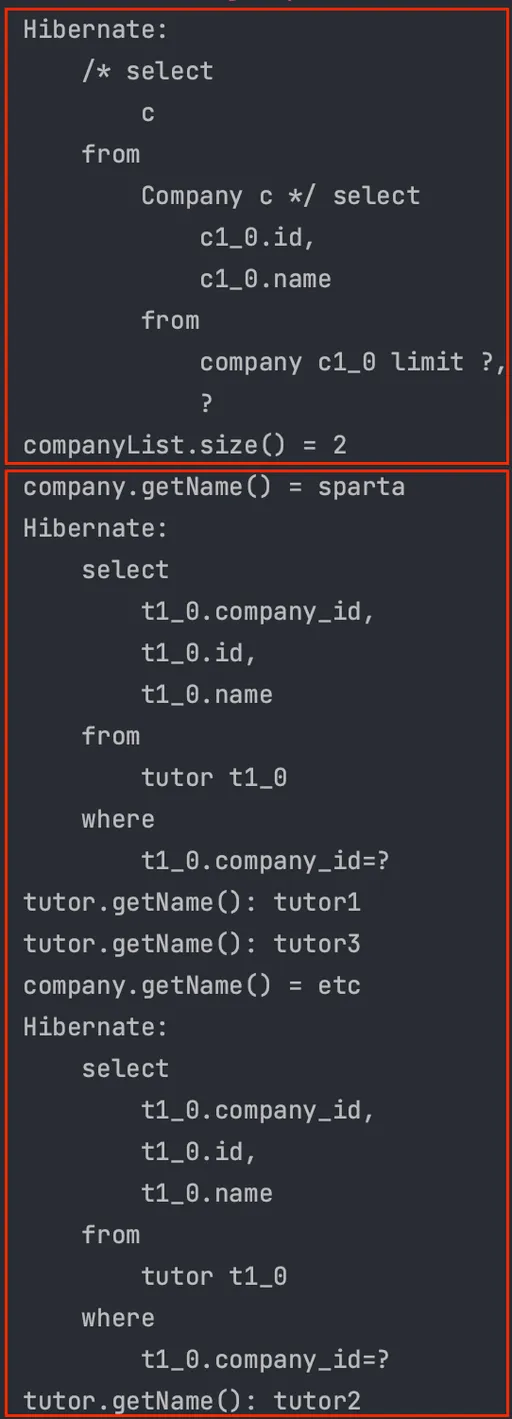
=> Company 전체 조회 후 조회 결과 2개(Sparta, etc)에 각각 지연로딩을 한다.
// 2. @BatchSize 적용 후
@BatchSize(size = 100)
@OneToMany(mappedBy = "company")
private List<Tutor> tutorList = new ArrayList<>();
=> 한 번의 IN Query에 식별자(PK)를 조회된 개수만큼 넣어준다.
설정 파일의 hibernate.jdbc.batch_size 를 통해 Global 적용이 가능하다.
4. 프로필 설정
Application.yml를 이용하여 프로필 환경별로 다른 설정을 적용할 수 있다.
@Slf4j
@Component
@Profile("dev")
public class DataInitializer {
@Autowired
private TutorRepository tutorRepository;
@Autowired
private StudentRepository studentRepository;
@PostConstruct
public void init() {
// Tutor 데이터 초기화
Tutor tutor1 = new Tutor("tutor1");
Tutor tutor2 = new Tutor("tutor2");
Tutor tutor3 = new Tutor("tutor3");
tutorRepository.save(tutor1);
tutorRepository.save(tutor2);
tutorRepository.save(tutor3);
// Student 데이터 초기화
for (int i = 0; i < 30; i++) {
Student student = new Student("student" + i, 20 + i);
// 튜터를 순차적으로 할당
if (i % 3 == 0) {
student.setTutor(tutor1);
} else if (i % 3 == 1) {
student.setTutor(tutor2);
} else {
student.setTutor(tutor3);
}
studentRepository.save(student);
}
log.info("===== Test Data Initialized =====");
}
}- @PostConstruct 로 Application 최초 실행 시에만 초기화 하도록 설정
- @Profile("dev") dev 프로필에서만 동작하도록 설정




