

이지은님의 블로그
250224 - Java Spring 심화: JPA를 활용한 연관관계와 상속관계 매핑, 프록시와 지연로딩, 영속성 전이, 트랜잭션 전파(@ManyToOne, @OneToMany, @Inheritance, FetchType.LAZY, CascadeType.ALL) 본문
250224 - Java Spring 심화: JPA를 활용한 연관관계와 상속관계 매핑, 프록시와 지연로딩, 영속성 전이, 트랜잭션 전파(@ManyToOne, @OneToMany, @Inheritance, FetchType.LAZY, CascadeType.ALL)
queenriwon3 2025. 2. 24. 23:47▷ 오늘 배운 것
Java Spring 심화 강의를 듣고 배우고 정리한 것을 블로그로 작성해보도록 하겠다.
<< 목차 >>
1. 연관관계 매핑
1-1) 1:N 단방향
1-2) 1:N 양방향
2-1) 1:1 단방향
2-2) 1:1 양방향
2-3) 1:1 연관관계의 특징
3-1) N:M 단/양방향
3-2) N:M 연관관계 특징
2. 상속관계 매핑
3. Proxy
1) proxy 개요
2) em.find() vs em.getReference()
3) 프록시(Proxy)
4) proxy 특징
4. 지연로딩과 즉시로딩
1) 지연로딩(Lazy Loading)
2) 즉시로딩(Eager Loading)
5. 영속성 전이
1) 영속성 전이 사용
2) Cascade
3) 고아객체
6. 트랙잭션 전파
1) 트랜잭션 전파(Propagation)
2) 트랜잭션 전파 종류
1. 연관관계 매핑
연관관계 매핑에서 사용하는 어노테이션
1️⃣ N:1: @ManyToOne
2️⃣ 1:N: @OneToMany
3️⃣ 1:1: @OneToOne
4️⃣ N:M: @ManyToMany
1-1) 1:N 단방향

1️⃣ Company
// Company entity
@OneToMany
@JoinColumn(name = "company_id")
private List<Tutor> tutors = new ArrayList<>();List.add()로 tutor 테이블 데이터 생성
2️⃣ Tutor
관계형 DB에서는 company_id(FK)가 자동 생성됨으로 연관관계 매핑

=> 실행시 Tutor 생성 -> Company 생성 -> 다시 Tutor 업데이트(객체와 테이블의 차이발생으로 어색한 구조)
-> 불필요한 쿼리가 실행되는 단점이 있으므로 N:1로 풀어야 한다.
그리고 @JoinColumn 미사용시, 중간테이블 방식이 사용된다.(company_tutor 테이블을 생성한다.)
1-2) 1:N 양방향
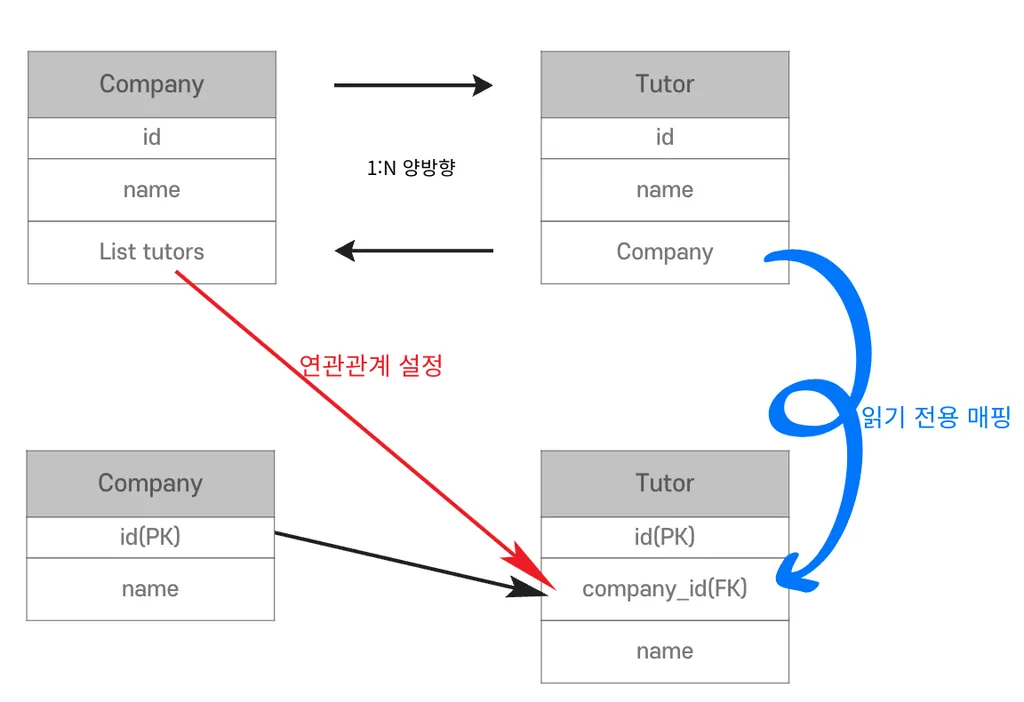
1️⃣ Company
// Company entity
@OneToMany
@JoinColumn(name = "company_id")
private List<Tutor> tutors = new ArrayList<>();
2️⃣ Tutor
// Tutor entity
@ManyToOne
@JoinColumn(name = "company_id", insertable = false, updatable = false)
private Company company;양방향으로 연결하되, Tutor 엔티티가 조회만 할 수 있도록 insertable = false, updatable = false를 설정한다.(주인 x)
=> 마찬가지로 불필요한 쿼리가 실행되는 단점이 있으므로 N:1로 풀어야 한다.
2-1) 1:1 단방향

1️⃣ Tutor(외래키 관리)
// Tutor entity
@OneToOne
@JoinColumn(name = "address_id", unique = true)
private Address address;1:1의 매핑에서는 외래키에 유니크 제약조건이 필요
2️⃣ Address
DB에서는 Address id가 tutor의 fk와 연결되는 pk의 역할을 한다.
=> 반대로 Address에 외래키 관리를 하게 한다면 이를 Tutor테이블이 관리하지 못한다.
=> 자신의 테이블에 있는 외래키만 관리 가능하다.
2-2) 1:1 양방향

1️⃣ Tutor(외래키 관리)
// Tutor entity
@OneToOne
@JoinColumn(name = "address_id", unique = true)
private Address address;외래키가 있는 곳이 연관관계의 주인
2️⃣ Address
// Address entity
@OneToOne(mappedBy = "address")
private Tutor tutor;양방향으로 연결하되, Address 엔티티가 조회만 할 수 있도록 mappedBy = "address"를 설정한다.(주인 x)
=> @OneByOne은 양방향을 할 시, 둘 중 하나에 mappedBy 설정필요
-> 자신이 가지는 외래키는 자신이 관리할 것
2-3) 1:1 연관관계의 특징
1️⃣ 외래키는 둘 중 모두 관리가능한다.
2️⃣ unique 제약조건만 지우면 N:1 연관관계로 변경가능하다.(양방향일 경우)
1:1 외래키 설정
| 주 테이블 | 대상 테이블 | |
| 장점 | - 객체 지향적인 개발 | - 데이터 무결성 보장 - 연관관계 변경시 테이블 구조가 유지됨 |
| 단점 | - 대상 테이블에 값이 없다면 null허용 -> 데이터 무결성 x - 삭제될 때 외래키를 처리할 수 있도록 관리 필요 |
- 조회 성능이 떨어지고, 매핑 설정이 복잡해진다. - 지연로딩으로 해도 즉시로딩으로 처리된다. |
=> 1:1 연관관계는 지양할 것
3-1) N:M 단/양방향
관계형 DB는 N:M 연관관계를 구현하지 못하므로 중간테이블을 생성하여 1:N, N:1 관계로 설정
1️⃣ 단방향
// Tutor entity
@ManyToMany
@JoinTable(
name = "tutor_language",
joinColumns = @JoinColumn(name = "tutor_id"),
inverseJoinColumns = @JoinColumn(name = "language_id")
)
private List<Language> languages = new ArrayList<>();joinColumns는 해당 entity,
inverseJoinColumns는 연관관계로 연결된 entity로 설정
2️⃣ 양방향
// Language entity
@ManyToMany(mappedBy = "languages")
private List<Tutor> tutors = new ArrayList<>();양방향으로 연결하되, languages 엔티티가 조회만 할 수 있도록 mappedBy = "languages를 설정한다.(주인 x)
=> 중간테이블 생성
=> 둘다 @ManyToMany를 설정하지만 둘중 하나를 주인으로 설정해야 한다.
3-2) N:M 연관관계 특징
- 실제 데이터 설계에는 중간테이블에 추가 데이터가 필요하다 -> @ManyToMany 사용 불가
- 중간테이블의 사용으로 사이드 이팩트 발생
- 중간테이블의 A_id, B_id를 묶어 외래키로 설정되어 사이드 이팩트가 발생한다.
=> 해결방법: 중간테이블을 엔티티로 직접 만들어 사용
2. 상속관계 매핑
| 설명 | dtype 사용 | Strategy | |
| 1️⃣ 단일 테이블 | 조인을 사용하여 각 테이블로 만들게 함 | ⭕️ | SINGLE_TABLE(default) |
| 2️⃣ 조인 | 하나의 테이블, 해당되는 것 외 필드를 null로 설정 | ⭕️ | JOINED |
| 3️⃣ 구현 클래스 | 각각의 분리된 테이블 | ❌ | TABLE_PER_CLASS |
1️⃣ 단일 테이블(default)
// Product entity(추상 클래스)
@DiscriminatorColumn(name = "dtype")
public abstract class Product {)
// Book entity(자식 클래스)
@DiscriminatorValue(value = "B")
public class Book extends Product {}
// Coat entity(자식 클래스)
@DiscriminatorValue(value = "C")
public class Coat extends Product {}JPA 단일 테이블 전략에서 @DiscriminatorColumn을 선언해 주지 않아도 기본으로 DTYPE 컬럼이 생성.
각 자식클래스의 dtype 값이 B와 C로 설정된다.
2️⃣ 조인(InheritanceType.JOINED)
// Product entity(추상 클래스)
@DiscriminatorColumn(name = "dtype")
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Product {}=> 생성시 3개의 테이블을 생성하고, 2개의 쿼리로 데이터를 삽입한다. 조회시 조인을 사용한 조회가 가능하다.
3️⃣ 구현 클래스(InheritanceType.TABLE_PER_CLASS)
// Product entity(추상 클래스)
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Product {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
}=> 생성: 테이블 각각 2개가 생성된다.
-> Product는 실제로 생성되는 테이블이 아니기 때문에 추상클래스 abstract를 사용한다.
-> 테이블이 각각 생성되기 때문에 id는 GenerationType.AUTO
-> 부모 클래스로 조회하면 모든 테이블을 조회하기 때문에 권장되지 않는다.
=> 공통 칼럼이 필요하면 JPA Auditing처럼 @MappedSuperclass를 사용할 것
| 1️⃣ 단일 테이블 | 2️⃣ 조인 | 3️⃣ 구현 클래스 | |
| InheritanceType | SINGLE_TABLE(default) | JOINED | TABLE_PER_CLASS |
| 장점 | - JOIN을 사용하지 않는다. - 실행되는 SQL이 단순하다. |
- 테이블 정규화 - 외래 키 참조 무결성 - 저장공간 효율 |
- 자식 클래스를 명확하게 구분해서 처리할 수 있다. - not null 제약조건 사용이 가능하다. |
| 단점 | - 자식 Entity가 매핑한 컬럼은 모두 null을 허용한다. - 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. - 상황에 따라서 조회 성능이 오히려 느려질 수 있다. |
- 조회시 JOIN을 많이 사용한다. - 데이터 저장시 INSERT SQL 이 2번 호출된다. - SQL Query가 복잡하여 성능이 저하될 수 있다. |
- 여러 자식 테이블을 함께 조회할 때 성능이 느리다. - 부모 객체 타입으로 조회할 때 모든 테이블을 조회해야 한다. |
| 선택 | 단순하고 확장 가능성이 없을 때 | 비지니스적으로 복잡할 때 | 테이블을 연관짓기 힘들어 권장❌ |
3. Proxy
1) proxy 개요
지연 로딩(Lazy Loading)을 활용해 데이터베이스 조회를 미루고 실제로 엔티티의 속성에 접근할 때만 데이터베이스를 조회하도록 하기 위해 proxy를 사용한다.
// 1. tutor의 company를 함께 조회하는 경우
Tutor findTutor = em.find(Tutor.class, 1L);
String tutorName = findTutor.getName();
Company tutorCompany = findTutor.getCompany();
// 2. tutor만 조회하는 경우
Tutor findTutor = em.find(Tutor.class, 1L);
String tutorName = findTutor.getName();- tutor의 company를 함께 조회하는 경우, Company와 매번 함께 조회가 된다.
- tutor만 조회하는 경우, Company 조회를 위해 추가적인 조회 SQL이 실행되어야 한다. => 프록시 사용
2) em.find() vs em.getReference()
// 1. em.find() 사용
Tutor findTutor = em.find(Tutor.class, tutor.getId());=> tutor와 company가 한꺼번에 실행된다.

// 2. em.getReference() 사용
Tutor proxyTutor = em.getReference(Tutor.class, tutor.getId());
proxyTutor.getName();=> proxyTutor: 조회쿼리가 실행되지 않음(프록시 객체)
=> proxyTutor.getName(): 인스턴스 값에 접근했을때 쿼리 실행(불필요한 쿼리 사용 줄임)

3) 프록시(Proxy)
데이터베이스 조회를 지연하는 가짜 객체(proxy)를 조회한다.
(실제 Entity와 == 비교 실패, instanceof 사용)

Target: 진짜 객체의 참조를 보관
후에 Proxy 객체를 진짜 Entity에 상속 시키며 진짜 객체 참조를 보관한다.

1️⃣ em.getReference(): 프록시 객체 조회
2️⃣ proxyTutor.getName() 호출
3️⃣ 영속성 콘텍스트에 target 초기화 (Entity target = null)
4️⃣ 실제 DB 조회
5️⃣ entity 생성
6️⃣ target의 부모 엔티티의 getName() 호출
4) proxy 특징
- 최초로 사용(실제 Entity에 접근)할 때 한 번만 초기화된다.
- 프록시 객체를 통해 실제 Entity에 접근할 수 있다.
- em.getReference() 호출 시 영속성 컨텍스트에 Entity가 존재하면 실제 Entity가 반환된다.
- 준영속 상태에서 프록시를 초기화하면 LazyInitializationException 예외가 발생한다. (준영속 상태: detach() : 영속성 컨텍스트가 관리하지 않는다.)
4. 지연로딩과 즉시로딩
1) 지연로딩(Lazy Loading)
: 지연로딩을 사용하면 Proxy 객체를 조회한다.
연관된 객체(Company)를 매번 함께 조회하는것은 낭비인 경우에 사용한다.
@OneToMany, @ManyToMany 의 기본 값 : 지연 로딩
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "company_id")
private Company company;=> Company까지 조회하지 않을 때 (Tutor만 조회, 프록시 객체로 조회한다.)
findTutor.getCompany().getName()=> 실제 값에 접근할 때 실제 엔티티의 쿼리가 실행된다.
2) 즉시로딩(Eager Loading)
: 연관된 데이터까지 모두 한번에 조회한다.
연관된 객체(Company)를 매번 함께 조회하는것이 효율적인 경우에 사용한다.
@ManyToOne, @OneToOne 의 기본 값 : 즉시 로딩
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "company_id")
private Company company;=> join을 이용해 한번의 SQL로 조회한다. 프록시를 사용하지 않는다.
=> 그러나 개발자가 예상하지 못한 쿼리가 실행될 수 있으며, N+1문제가 발생한다.
5. 영속성 전이
1) 영속성 전이 사용
: 영속성 전이(Cascade)란 JPA에서 특정 엔티티를 저장, 삭제 등의 작업을 할 때 연관된 엔티티에도 동일한 작업을 자동으로 적용하도록 설정하는 기능이다.
단일 Entity에 완전히 종속적인 경우 생명주기가 같다면 사용한다.
속성 종류
- ALL : 모두 적용
- PERSIST : 영속
- REMOVE : 삭제
2) Cascade
@OneToMany(mappedBy = "category", cascade = CascadeType.ALL)
private List<Product> productList = new ArrayList<>();=> category의 product 2개를 add 후, em.persist(category)를 하면 3개의 쿼리가 실행된다.
3) 고아객체
: 부모엔티티와 연관관계가 끊어진 자식엔티티
(orphanRemoval = true 사용)
- 참조하는 곳이 하나인 경우에만 사용한다.
- 단일 Entity에 완전히 종속적인 경우 생명주기가 같다면 사용한다.
- @OneToOne, @OneToMany만 사용이 가능하다.
- 부모 Entity를 제거하면 자식 Entity는 고아 객체가 된다.
- CascadeType.REMOVE와 비슷하게 동작한다.
CascadeType.ALL과 orphanRemoval=true 를 함께 사용하는 경우 부모 Entity를 통해서 자식 Entity의 생명주기를 관리할 수 있다. 도메인 주도개발(Domain Driven Design)에 주로 사용한다.
// 1. cascadeType.ALL 사용
@OneToMany(mappedBy = "category", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Product> productList = new ArrayList<>();findCategory.getproductList().remove(0) 사용
=> Collection에서 제거된 객체는 삭제된다.(고아 객체)

// 2. cascadeType.ALL 제거
@OneToMany(mappedBy = "category", orphanRemoval = true)
Collection이 제거되었기 때문에 모두 삭제한다.private List<Product> productList = new ArrayList<>();em.remove(findCategory) 사용
=> Collection이 제거되었기 때문에 모두 삭제한다.

6. 트랙잭션 전파
: 하나의 트랜잭션이 다른 트랜잭션 내에서 어떻게 동작할지를 결정하는 규칙으로 여러 개의 트랜잭션이 포함된 시스템에서 특정 작업이 다른 작업에 어떻게 영향을 미칠지를 정의한다.
1) 트랜잭션 전파(Propagation)
- 트랜잭션이 여러 계층 또는 메서드에서 어떻게 처리될지 정의한다.(@Transactional)
- propagation 속성을 통해 트랜잭션의 동작 방식을 제어할 수 있다.
- 다양한 비즈니스 요구 사항에 맞춰 복잡한 트랜잭션 흐름을 유연하게 설계할 수 있도록 돕는다.
- 데이터 무결성과 비지니스 로직의 안정성을 보장할 수 있다.
// 1. REQUIRED 사용
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
public void addPoints(Long memberId, int points) {
...
}
}=> @Transactional 을 통해 트랜잭션 설정되어 하위 addPoints() 메서드에 트랜잭션이 전파된다. 실패할 시 signUp()모두 실패해 롤백한다.
// 2. REQUIRES_NEW 사용
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addPoints(Long memberId, int points) {
...
}
}=> REQUIRES_NEW설정으로 독립적인 트랜잭션 설정이 가능하다. 해당 메서드가 실패해도 그 메서드만 롤백된다.
2) 트랜잭션 전파 종류
1️⃣ REQUIRED(Default)
- 기존 트랜잭션이 있다면 기존 트랜잭션을 사용한다.
- 기존 트랜잭션이 없다면 트랜잭션을 새로 생성한다.
2️⃣ REQUIRES_NEW
- 항상 새로운 트랜잭션을 시작하고, 기존의 트랜잭션은 보류한다.
- 두 트랜잭션은 독립적으로 동작한다.
3️⃣ SUPPORTS
- 기존 트랜잭션이 있으면 해당 트랜잭션을 사용한다.
- 기존 트랜잭션이 없으면 트랜잭션 없이 실행한다.
4️⃣ NOT_SUPPORTED
- 기존 트랜잭션이 있어도 트랜잭션을 중단하고 트랜잭션 없이 실행된다.
5️⃣ MANDATORY
- 기존 트랜잭션이 반드시 있어야한다.
- 트랜잭션이 없으면 실행하지 않고 예외를 발생시킨다.
6️⃣ NEVER
- 트랜잭션 없이 실행되어야 한다.
- 트랜잭션이 있으면 예외를 발생시킨다.
7️⃣ NESTED
- 현재 트랜잭션 내에서 중첩 트랜잭션을 생성한다.
- 중첩 트랜잭션은 독립적으로 롤백할 수 있다.
- 기존 트랜잭션이 Commit되면 중첩 트랜잭션도 Commit 된다.
REQUIRED과 REQUIRES_NEW를 주로 사용한다.



