

이지은님의 블로그
250204 - Java Spring과 CS개념: 클라우드, 데이터 교환, 연관관계, 객체지향(SOLID원칙, IoC와 DI) 본문
250204 - Java Spring과 CS개념: 클라우드, 데이터 교환, 연관관계, 객체지향(SOLID원칙, IoC와 DI)
queenriwon3 2025. 2. 4. 20:33▷ 코드 문제풀이
[JAVA] 코드카타 - (61)~(65)
문제 (61) : 로또의 최고 순위와 최저 순위로또 6/45(이하 '로또'로 표기)는 1부터 45까지의 숫자 중 6개를 찍어서 맞히는 대표적인 복권입니다. 아래는 로또의 순위를 정하는 방식입니다. 1순위당첨
queenriwon3.tistory.com
▷ 오늘 배운 것
오늘은 스탠다드반 강의자료와 숙련 Spring 1주차 강의를 함께 정리해보았다.
<< 목차 >>
1. 백엔드와 프론트엔드 차이점
2. 클라우드 서비스
1) 클라우드
2) 클라우드 서비스: Iaas, Paas, Saas
3. 데이터 교환
1) JSON
2) API
3) SSH
4. Java 개념과 객체지향의 원칙
1) 클래스와 객체와 인스턴스
2) Static 멤버란?
3) SOLID원칙
4) IoC와 DI (Spring)
5. 연관관계
1) 연관관계 매핑이란?
2) 단방향과 양방향
3) 연관관계 유형
4) Cascade와 FetchType 설정
1. 백엔드와 프론트엔드 차이점
| 백엔드 | 프론트엔드 | |
| 역할 | 데이터 처리, 비즈니스 로직, 데이터베이스 관리 등 서버 측 작업을 담당 | 사용자가 상호작용하는 UI와 UX를 개발 |
| 기술스택 | Java, Kotlin, Python, Node.js, Spring, Django, Express 등. | HTML, CSS, JavaScript, React, Angular, Vue.js 등. |
| 작동 원리 | 클라이언트(프론트엔드) 요청을 처리하고, 필요한 데이터를 반환하거나 특정 작업을 수행. | 백엔드에서 받은 데이터를 화면에 보여주고, 사용자 입력을 처리. |
| 결과물 | API 및 데이터 처리 결과를 제공. | 웹 브라우저에서 실행되는 시각적 요소를 제공. |
2. 클라우드 서비스
1) 클라우드
클라우드란?
내가 아닌 다른 회사의 공급자가 호스팅하고 인터넷을 통해 사용자에게 제공되는 인프라, 플랫폼 또는 소프트웨어.
자체 인프라나 하드웨어 설치 없이도 애플리케이션과 리소스에 쉽고 싸게 이용이 가능하다.
이렇게 되면 서버를 직접 구매할 때 고려해야 할 전력, 위치, 서버 세팅, 확장성을 고민하지 않고 서비스 운영에만 집중할 수 있다.
➡️ 오프프레미스(off-premise) 방식
➡️ 온-프레미스(on-premise) 방식: 기업이나 개인이 자체 시설에서 보유하고 직접 유지 관리하는 프라이빗 데이터 센터(IDC)
예를 들어, 네이버의 데이터센터 등이 있다.
2) 클라우드 서비스: Iaas, Paas, Saas
| Iaas (Infrastructure-as-a-Service) |
Paas (Platform-as-a-Service) |
Saas (Software as a Service) |
|
| 서비스 | 인프라형 클라우드 서비스 | 플랫폼형 클라우드 서비스 | 서비스형 클라우드서비스 |
| 특징 | 클라우드가 인프라만 제공 node.js, MongoDB 등을 개발자가 직접 설치해야 하는 대신 특정 서비스에 종속되지 않는다. |
클라우드가 플랫폼을 제공 Node.js, MongoDB 등이 설치되어있으며 클릭을 통해 해당 서비스를 쉽게 이용할 수 있다. 모니터링 CI/CD가 제공된다. |
완전한 서비스를 클라우드 서비스로부터 제공받아 사용 |
| 비교 | 유연하며 플랫폼에 종속되지 않음. 이식성이 높으며, 운영비 효율이 낮다 |
유연하지 않으며 플랫폼에 종속. 이식성은 낮으나 운영비 효율이 높다. |
3. 데이터 교환
1) JSON: 직렬화와 역직렬화
JSON(JavaScript Object Notation)이란,
Javascript 객체 문법 으로 구조화된 데이터교환형식, python, javascript, java 등 여러 언어에서 데이터 교환형식으로 쓰이며 객체문법말고도 단순 배열, 문자열도 표현이 가능하다.
Key-value 구성
JSON의 직렬화(JSON.parse())란,
외부의 시스템에서도 사용할 수 있도록 바이트 형태로 데이터를 변환하는 기술(↔️ 역직렬화(JSON.stringify())
2) API
API(Application Programming Interface)란,
둘 이상의 컴퓨터 프로그램이 서로 통신하는 방법이자 컴퓨터 사이에 있는 중계 계층을 의미한다.
예를 들어 2대의 컴퓨터 사이의 데이터 통신 방법이 정의된 중간계층…
사용자가 브라우저를 통해 서버에 요청을 하게 되면, API가 중간계층역할을 하며 요청을 처리하는 것을 볼 수 있다. 또한, 직접 서버의 데이터베이스에 접근하는 것을 방지하기도 한다.
인터페이스(interface)란,
서로 다른 두 개의 시스템, 장치 사이에서 정보나 신호를 주고받는 경우의 접점이나 경계면을 말한다. 인터페이스를 통해 해당 컴퓨터의 내부서버가 어떻게 구현되어있는지는 상관없이 인터페이스를 통해 통신 등이 가능하다.
API의 장점
- 제공자는 서비스의 중요한 부분(DB설계 구조 등..)을 드러내지 않아도 된다.
- 사용자는 해당 서비스가 어떻게 구현되는지 알 필요없이 필요한 정보만을 받을 수 있습니다.
- OPEN API의 경우 앱 개발 프로세스를 단순화 시키고 시간과 비용을 절약할 수 있습니다.
- 매번 수정하는 것이 아닌 API가 수정이 안 되게 만들 수도 있다. 이를 통해 내부 DB, 서버의 로직이 변경이 되어도 매번 사용자가 앱을 업데이트하는 일이 줄어든다.
- 제공자는 데이터를 한곳에 모을 수 있다.
API의 종류
- private : 내부적으로 사용. 주로 해시키를 하드코딩해놓고 이를 기반으로 서버와 서버간의 통신을 한다.
- public : 모든 사람이 사용할 수 있다. 많은 트래픽을 방지하기 위해 하루 요청수의 제한, 계정당 몇개 등으로 관리한다.
3) SSH
SSH(Secure Shell Protocol)는 보안되지 않은 네트워크에서 네트워크 서비스를 안전하게 운영하기 위한 암호화 네트워크 프로토콜.
보통 프라이빗 키가 있는 경로에서 이런식으로 키를 명시하고 실행한다.
ssh <pem> <user>@<serverIP>
4. Java 개념과 객체지향의 원칙
1) 클래스와 객체와 인스턴스
클래스 : 클래스(class)란 객체(object)를 만들어 내기 위한 틀이며 만들어 낼 객체의 속성과 메서드의 집합을 담아놓은 것
객체 : 클래스로부터 만들어지는 실체, 클래스로 선언된 변수
인스턴스 : 객체가 메모리에 할당이 된 상태이며 런타임에 구동되는 객체(또는 AWS의 클라우드의 가상서버)
2) Static 멤버란?
static 키워드는 클래스의 인스턴스가 아닌 클래스에 속하며 클래스의 변수, 메서드 등을 공유하는데 사용된다.
이를 통해 해당 클래스로 만들어지는 객체사이에서 중복되는 메서드, 속성을 효율적으로 정의할 때 쓰이며, 단순히 전역변수가 아니라 클래스내의 static 키워드로 선언하여 이 클래스의 객체들끼리 사용되는 메서드 또는 속성이다. 라는 것을 나타내주는 명시성이라는 장점이 생기기 때문에 씁니다.
static 키워드로 선언된 변수, 블록, 메서드 등은 선언과 동시에 미리 heap영역이 아닌 Method area 메모리 영역에 할당이 되며 프로그램이 종료 될 때까지 GC에 의해 메모리가 회수되지 않기 때문에 만약 클래스가 객체로 쓰이지 않는다면 메모리 낭비가 생긴다.
3) SOLID원칙
1️⃣ 단일 책임 원칙 SRP(Single Responsibility Principle)
: 하나의 클래스는 한가지 기능에 집중해야하며, 그외의 기능을 담당하지 않아야한다.(클래스가 변경될 때 그 파급효과가 작아야한다.)
2️⃣ 개방 폐쇄 원칙 OCP(Open Closed Principle)
: 소프트웨어 요소는 확장에는 열려있어야하고, 수정에는 닫혀있어야 한다.
—> 새로운 기능을 추가할 때, 기존 코드를 수정하지 않고, 확장할 수 있도록 설계한다.
—> 구현: 인터페이스 사용
3️⃣ 리스코프 치환 원칙 LSP(Liskov Substitution Principle)
: 자식클래스는 언제나 부모클래스를 대체할 수 있어야 한다.
—> 부모 클래스를 사용하는 곳에서 자식 클래스를 사용해도 프로그램의 동작에 문제가 없어야 한다.
4️⃣ 인터페이스 분리 원칙 ISP(Interface Segregation Principle)
: 하나의 큰 인터페이스보다는 여러 개의 작은 인터페이스로 분리해야 한다.
—> 구현: 여러개의 인터페이스를 다중 상속
5️⃣ 의존관계 역전 원칙 DIP(Dependency Inversion Principle)
: 구체적인 클래스에 의존하지 말고, 인터페이스나 추상 클래스에 의존하도록 설계해야 한다.
interface Notifier {
void send(String message);
}
class EmailNotifier implements Notifier {...}
Notifier emailNotifier = new EmailNotifier();알림기능에 여러기능 알림이 존재한다.
특정 기능에 알림기능을 부여하는 것보다 여러 알림기능을 객체 외부에서 주입받는 방식을 택하여, 세부사항에 대해 몰라도 되며, 의존성이 약해진다.
이때, Spring은 OCP, DIP 원칙을 지킬 수 있도록 도와주며, 코드의 변경 없이 기능을 확장할 수 있도록 만들어 준다.
4) IoC와 DI (Spring)
제어(Control)이란?
프로그램의 실행 흐름과 객체의 생명 주기를 개발자가 직접 관리하는 것을 의미한다.
의존성이 많아질수록 객체간 결합도가 높아져 코드 변경 및 테스트가 어렵다.
1️⃣ IoC(Inversion of Control, 제어의 역전)이란?
프로그램의 실행 흐름과 객체의 생성, 관리를 개발자가 아닌 컨테이너(Spring)가 담당하도록 하는 개념.
객체는 필요한 의존성을 컨테이너에서 제공받아 사용한다.
—> 객체간의 결합도를 낮춰 유연한 코드가 된다.
 |
➡️ | 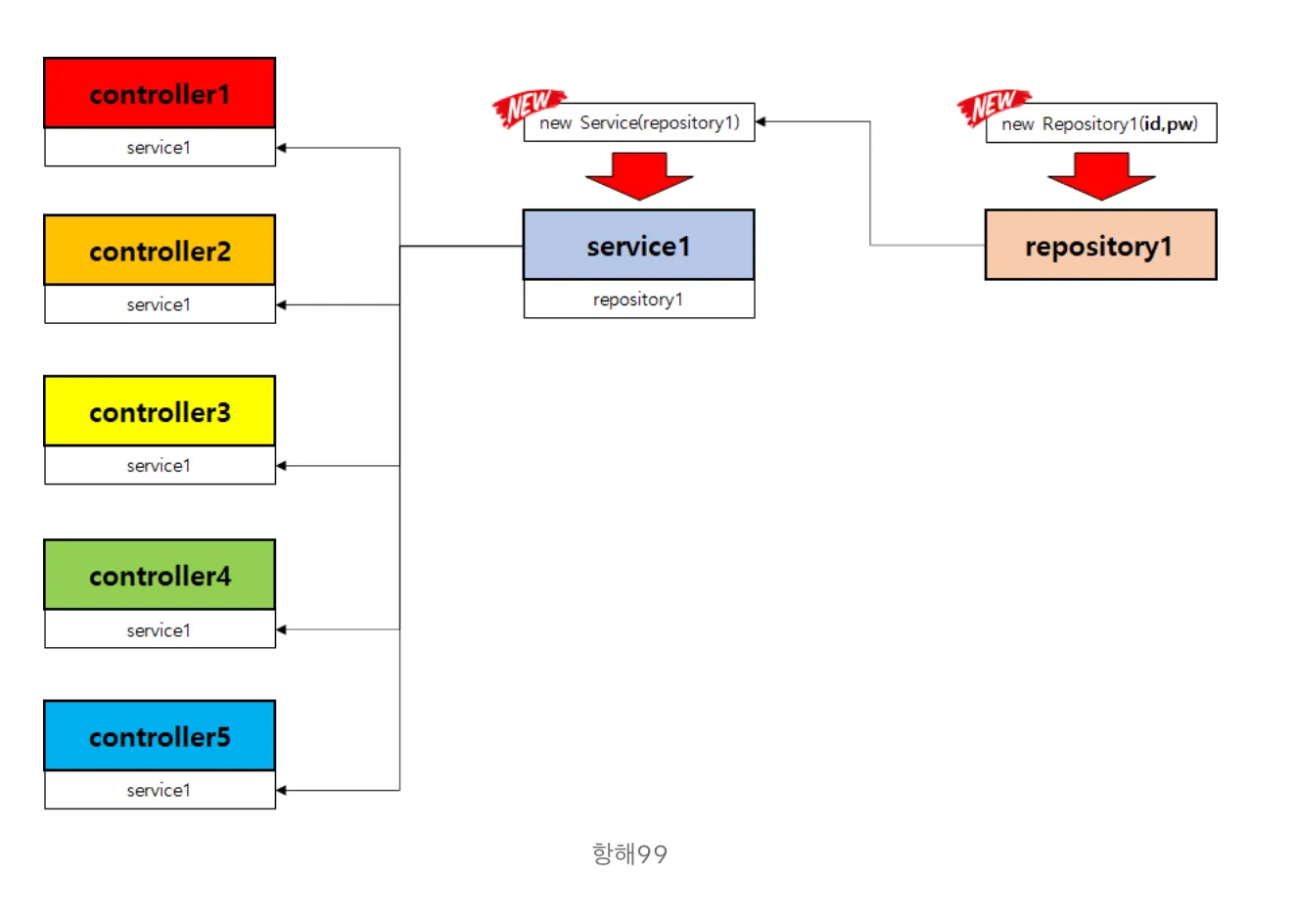 |
이처럼 하나의 Controller마다 새로운 여러 객체들을 항상 만들어서 사용할 필요가 없고, 이미 생성했던 객체의 멤버 변수들을 재사용한다.
—> 이런 흐름이 바뀌는 행위를 제어의 역전이라고 한다.
이렇게 될 경우, 객체의 생명주기와 의존성 관리를 개발자가 신경쓰지 않아도 된다. 코드의 결합도를 낮추고 유연성을 높일 수 있다.
👉 객체의 생명 주기
객체가 생성되고 사용된 후 소멸되기까지의 과정(객체 생성 → 의존성 주입 → 초기화 → 사용 → 소멸), 적절히 관리되지 않으면 성능 문제나 메모리 누수(memory leak)가 발생
2️⃣ DI(Dependency Injection, 의존성 주입)이란?
IoC의 구현 방법 중 하나로, 객체가 사용할 의존성을 직접 생성하지 않고 외부에서 주입받는 방식.
DI의 종류
| Constructor Injection (생성자 주입) |
Setter Injection (세터 주입) |
Field Injection (필드 주입) |
|
| 설명 | 생성자를 통해 의존성을 주입 받음 | 메서드를 통해 의존성을 주입 받음 | 필드에 바로 의존성을 주입받을 수 있음 |
| 장점 | 필드 불변성 보장 | 선택적 의존성 주입가능 | 코드 간결, 가독성 |
| 단점 | 필드가 많아질시 생성자 길어짐 | 객체가 불완전한 상태로 생성될 수 있음 | 테스트 어려움, DI 프레임워크에 강한 의존 |
| 권장여부 | 가장 권장 | 가끔 | 권장되지 않음 |
// 생성자 주입방법
@Component("adidasBall") //Spring이 해당 클래스를 자동으로 Bean으로 등록하도록 해주는 어노테이션
public class AdidasSoccerBall implements SoccerBall {
public String touchBall() {
return "아디다스 축구공이 굴러간다!";
}
}
@Component
public class SoccerPlayer {
private final SoccerBall ball;
@Autowired // Spring이 생성자를 통해 의존성 주입
public SoccerPlayer(@Qualifier("adidasBall") SoccerBall ball) {
this.ball = ball;
}
public String playSoccer() {
return "축구선수가 공을 찼다! \n" + ball.touchBall();
}
// 세터 주입 방법
// @Autowired
// public void setBall(SoccerBall ball) {
// Setter 메서드에 주입
// this.ball = ball;
// }
// 필드 주입 방법
// @Autowired
// private SoccerBall ball;
}
3️⃣ 다시 SOLID원칙의
의존 역전 원칙(DIP, Dependency Inversion Principle)
: 클래스가 구체적인 구현체에 직접 의존하지 않고, 인터페이스에 의존한다.
생성할 때 구현체를 생성해주면 생성자에 의해서 원하는 기능을 할 수 있음
// 강한 결합
class SoccerPlayer {
private AdidasSoccerBall ball;
public SoccerPlayer() {
this.ball = new AdidasSoccerBall(); // 직접 생성 (강한 결합)
}
}
// DI 적용 후 (느슨한 결합)
class SoccerPlayer {
private SoccerBall ball;
public SoccerPlayer(SoccerBall ball) { // 생성자 주입 (DI)
this.ball = ball;
}
}
이를 Spring에서 어떻게 활용할 수 있을까?
// 의존성 주입을 위한 Bean등록
@Component("adidasBall") // Bean으로 등록
public class AdidasSoccerBall implements SoccerBall {
public String touchBall() {
return "아디다스 축구공이 굴러간다!";
}
}
@Component // SoccerPlayer도 Bean으로 등록
public class SoccerPlayer {
@Autowired
@Qualifier("adidasBall") // 이름으로 Bean을 주입
private SoccerBall ball;
public String playSoccer() {
return "축구선수가 공을 찼다! \n" + ball.touchBall();
}
}
// 컨트롤러에서 활용 가능
@RestController
public class SoccerController {
@Autowired
private SoccerPlayer soccerPlayer;
@RequestMapping("/soccer")
public String soccerDriver() {
return soccerPlayer.playSoccer();
}
}
5. 연관관계
1) 연관관계 매핑이란?
데이터베이스에서 엔티티 간 관계를 정의하고, 이를 ORM을 통해 객체지향적으로 표현하는 것.
현대적인 애플리케이션에서는 여러 개의 엔티티(Entity)들이 서로 연관되어 있으며, 이러한 관계를 올바르게 설정해야 한다. Spring Boot와 JPA를 사용하면 객체 간의 관계를 기반으로 데이터베이스 테이블 간의 관계를 매핑
매핑의 장점
- 데이터의 정합성(Consistency) 유지 - 어떤 데이터들이 값이 서로 일치하는 상태를 의미
- 중복 데이터 최소화 및 정규화
- 비즈니스 로직의 직관적인 표현 가능
- 객체 간의 관계를 직접 코드에서 표현하여 가독성과 유지보수성 향상
- SQL JOIN을 활용한 최적화된 데이터 조회 가능
관계형 데이터베이스와 객체지향의 차이점
| 비교 항목 | 객체지향(OOP) | 관계형 DB(RDB) |
| 데이터 모델 | 객체(클래스) | 테이블 |
| 관계 표현 방식 | 참조(Reference) | 외래 키(FK) |
| 상속 구조 | 상속 지원 | 테이블 설계 필요(JOIN) |
| 데이터 저장 방식 | Heap 메모리 | 디스크 구조 |
| 탐색 방법 | 객체 그래프 탐색(몰라도됨) | SQL JOIN 활용 |
—> JPA같은 ORM 기술을 도입하여 객체와 테이블 간의 관계를 자동으로 매핑
2) 단방향과 양방향
| 단방향 관계 | 양방향 관계 | |
| 참조 | 한 엔티티에서만 다른 엔티티를 참조하는 경우 | 두 엔티티가 서로 참조하는 경우(주인 개념 필요) |
| 조회 | 외래 키를 포함한 엔티티에서만 연관된 엔티티를 조회 가능 | 양쪽 엔티티에서 상대 엔티티를 조회할 수 있음 |
- 주인이 아닌 엔티티의 필드는 mappedBy 속성 사용
- 연관 관계의 주인은 외래키를 가진 엔티티
3) 연관관계 유형
1️⃣ 1:1 관계(OneToOne)
@Entity
public class UserInfo {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
// 1:1관계
@JoinColumn(name = "profile_id") // 외래 키 지정
private Profile profile;
}
@Entity
public class Profile {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String bio;
@OneToOne(mappedBy = "profile")
private UserInfo userInfo;
}- @JoinColumn 을 통해 외래 키 지정 가능
- 양방향일 경우 mappedBy 를 사용하여 연관 관계의 주인 설정
- FetchType.LAZY: 지연로딩을 사용하여 필요할 때만 가져오도록 최적화 가능
2️⃣ 1:N (OneToMany) & N:1 (ManyToOne) 관계
// Team ↔ Member (한 팀에는 여러 멤버가 속함)
@Entity
public class Team {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
private List<Member> members = new ArrayList<>();
}
@Entity
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id") // 외래 키 설정
private Team team;
}- @OneToMany(mappedBy = "team"): mappedBy 사용 시 외래 키 관리 X (연관 관계의 주인이 아님)
- @ManyToOne(fetch = FetchType.LAZY): ManyToOne 관계에서 외래 키 관리(연관관계 주인임)
- N:1 관계에서 외래 키를 가진 쪽이 연관 관계의 주인
- cascade = CascadeType.ALL: Team 삭제 시 Member 도 삭제됨
3️⃣ N:N (ManyToMany) 관계
// Student ↔ Course (한 학생이 여러 강의를 들을 수 있고, 하나의 강의는 여러 학생이 수강 가능)
@Entity
public class Student {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany
// 중간테이블 명시
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses = new ArrayList<>();
}
@Entity
public class Course {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@ManyToMany(mappedBy = "courses")
private List<Student> students = new ArrayList<>();
}- @ManyToMany 를 사용하면 JPA가 자동으로 중간 테이블을 생성해준다.
- @JoinTable 사용하여 중간 테이블의 컬럼을 명시할 수 있음
- 실무에서는 N:M 관계는 중간 테이블을 만들어 1:N, N:1 관계(매핑 테이블)로 풀어내는 것이 일반적 (추가 필드 관리가 어려움)
4) Cascade와 FetchType 설정
1️⃣ Cascade (영속성 전이)
| Cascade 옵션 | 설명 |
| CascadeType.ALL | 모든 변경 사항을 전파 (저장, 삭제 등) |
| CascadeType.PERSIST | 저장(CREATE) 시 전파 |
| CascadeType.MERGE | 병합(UPDATE) 시 전파 |
| CascadeType.REMOVE | 삭제(DELETE) 시 전파 |
| CascadeType.DETACH | 부모 엔티티가 분리될 때 자식도 분리 |
// CascadeType.ALL 을 설정하면 Team 을 저장하면 Member 도 자동으로 저장
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
private List<Member> members = new ArrayList<>();
@Transactional
public void saveTeamWithMembers() {
Team team = new Team();
team.setName("Development Team");
Member member1 = new Member();
member1.setName("Alice");
Member member2 = new Member();
member2.setName("Bob");
// 연관관계 설정
team.addMember(member1);
team.addMember(member2);
// 팀을 저장하면 멤버도 자동 저장됨
teamRepository.save(team);
}—> 내부적으로 실행되는 쿼리
INSERT INTO team (name) VALUES ('Development Team');
INSERT INTO member (name, team_id) VALUES ('Alice', 1);
INSERT INTO member (name, team_id) VALUES ('Bob', 1);
// Team 삭제 시 Member 도 자동으로 삭제됨
@Transactional
public void deleteTeam(Long teamId) {
Team team = teamRepository.findById(teamId).orElseThrow();
teamRepository.delete(team); // -> 연관된 Member 데이터도 삭제됨
}—> 내부적으로 실행되는 쿼리
DELETE FROM member WHERE team_id = 1;
DELETE FROM team WHERE id = 1;
Cascade 권장 사용 예시
- @OneToMany 관계에서 자식 엔티티의 생명주기가 부모 엔티티에 종속될 때
- @OneToOne 관계에서 하나의 부모 엔티티가 하나의 자식 엔티티를 완전히 소유하는 경우
Cascade 비권장 사용 예시
- @ManyToOne 관계에서 남용할 경우 데이터 손실 위험
- @ManyToMany 관계에서 데이터 삭제 시 복잡한 의도치 않은 삭제가 발생할 가능성이 있음
2️⃣ FetchType (즉시 로딩 vs 지연 로딩)
| FetchType | 설명 |
| FetchType.EAGER | 즉시 로딩 (JOIN을 통해 연관된 엔티티 즉시 조회) |
| FetchType.LAZY | 지연 로딩 (필요할 때 조회, 프록시 객체로 대체) |
// 즉시 로딩(EAGER) 예제
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "team_id")
private Team team;
// Member를 조회하면 즉시 Team도 함께 조회됨 불필요한 데이터 조회로 성능 이슈 발생 가능
// 지연 로딩(LAZY) 예제
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
// Member 를 조회할 때 Team 은 조회되지 않고, 필요할 때 쿼리가 실행됨 권장 방식 (필요한 데이터만 로딩하여 성능 최적화)


