

이지은님의 블로그
250317 - Java Spring 일정 과제 과정과 트러블 슈팅: 테스트 컨트롤러, AOP, CascadeType.persist, N+1, QueryDSL 동적쿼리 및 Projection, Propagation 본문
250317 - Java Spring 일정 과제 과정과 트러블 슈팅: 테스트 컨트롤러, AOP, CascadeType.persist, N+1, QueryDSL 동적쿼리 및 Projection, Propagation
queenriwon3 2025. 3. 18. 00:32▷ 오늘 배운 것
과제를 해결한 과정과 트러블 슈팅에 대해서 정리해보려고 한다.
<<목차>>
1. Lv1-1. 코드 개선
2. Lv.1-2. 엔티티의 속성 추가
3. Lv.1-3. 검색조회기능
4. Lv.1-4. 테스트 컨트롤러
5. Lv.1-5. AOP
6. Lv.2-1. CascadeType.persist
7. Lv2-2. N+1
8. Lv2-3. QueryDSL
9. Lv.2-4. Spring Security
1) 유효하지 않은 UserRole (🚨 트러블 슈팅)
2) 테스트 코드 (🚨 트러블 슈팅)
10. Lv.3-1. QueryDSL 을 사용하여 검색 기능
1) QueryDSL 의 동적쿼리
2) Projection
3) group by 사용하여 구현
4) 서브쿼리 사용 (🚨 트러블 슈팅)
11. Lv.3-2. Propagation.REQUIRES_NEW를 이용하여 요청로그 저장
1. Lv1-1. 코드 개선
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class TodoService {
private final TodoRepository todoRepository;
private final WeatherClient weatherClient;
@Transactional
public TodoSaveResponse saveTodo(AuthUser authUser, TodoSaveRequest todoSaveRequest) {
User user = User.fromAuthUser(authUser);
}
}TodoService 클래스 단위로 @Transactional(readOnly = true)가 설정되어 있어, 일정을 저장(save)하는 메서드는 따로 @Transactional(readOnly = false)로 설정해줘야 한다.
조회만 하는 트랜잭션의 경우 @Transactional(readOnly = true)가 다른 부가적인 쿼리문이 사용되지 않도록 막는다. 쓰기(INSERT, UPDATE, DELETE)는 하지 않으므로 데이터베이스의 최적화를 돕는다.
다른 저장/수정/삭제의 트랜잭션의 경우는 false로 설정해준다.
@Transactional(readOnly = true)의 특징
1️⃣ 변경감지(더티 체킹) 비활성화 -> 메모리 효율
2️⃣ 성능향상 -> 조회전용 트랜잭션 최적화
3️⃣ 실수방지 -> 실수로 데이터를 변경하는 코드 방지
2. Lv.1-2. 엔티티의 속성 추가
orm을 사용하는 이점 중 하나는 엔티티에서 필드를 하나 추가 하는 등의 수정이 있더라도 쉽게 추가하여 사용할 수 있다는 점이다. 따라서 요구사항에 맞게 nickname 필드를 추가했다.
@Getter
@Entity
@NoArgsConstructor
@Table(name = "users")
public class User extends Timestamped {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String email;
private String nickname; // 추가
private String password;
@Enumerated(EnumType.STRING)
private UserRole userRole;
public User(String email, String nickname, String password, UserRole userRole) {
this.email = email;
this.nickname = nickname;
this.password = password;
this.userRole = userRole;
}
}
(제일 아래 사용자 정보를 제외한 행들은 전부 nickname 필드가 추가되기 전에 생성된 것)
프론트엔드 개발자가 JWT에서 유저의 닉네임을 꺼내 화면에 보여줘야한다는 요구사항에 따라 jwt에 nickname을 저장하고 이를 출력할 수 있도록 구현했다.
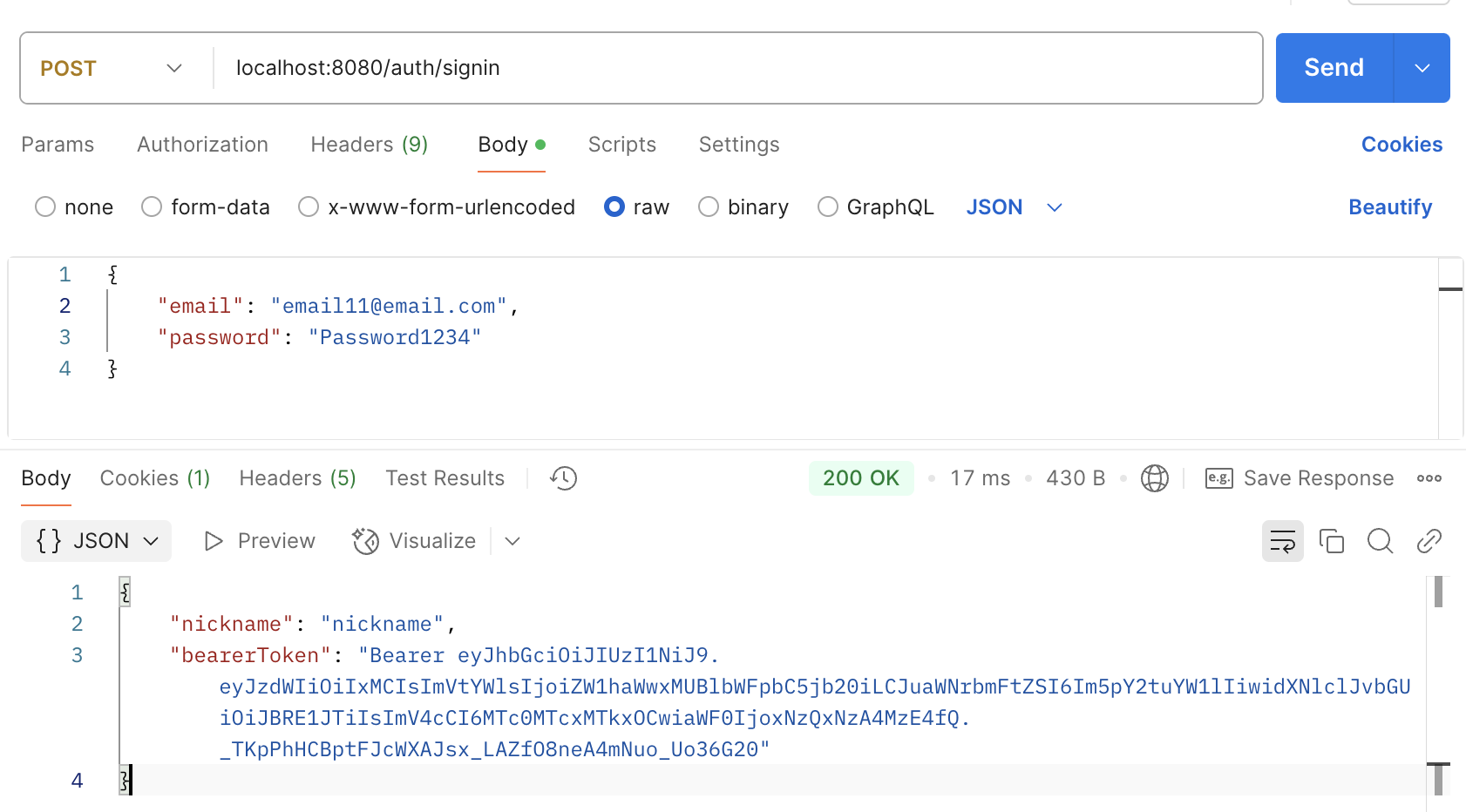
3. Lv.1-3. 검색조회기능
검색조회 기능의 경우 두가지 조건이 있다. weather와 수정일이다. 그런데 조건이 있을 수도 없을 수도 있다는 점에서 Query DSL을 사용한 동적쿼리를 작성하고 싶었으나, 요구사항이 JPQL이었기 때문에 각 요구사항에 따른 메서드를 작성하여 구현했다.
수정일의 endAt은 현재 시간을 뛰어넘을 수 없다. 따라서 endAt이 입력되지 않았을 경우(null) 현재시간으로 자동 설정된다. 따라서 endAt이 null일 경우가 없다.
그럼 다음과 같은 조건문이 나온다.
1️⃣ 전체 검색 (weather == null && startAt == null)
2️⃣ 날씨 조건으로 검색 (weather != null && startAt == null)
3️⃣ 수정일 시작으로 검색 (weather == null && startAt != null)
4️⃣ 날씨와 수정일 시작 조건으로 검색 (weather != null && startAt != null)
// Service
Pageable pageable = PageRequest.of(page - 1, size);
if (endAt == null) { // endAt은 무조건 존재함
endAt = LocalDate.now();
}
Page<Todo> todos;
if (weather == null && startAt == null) { // 전체 검색
todos = todoRepository.findAllByOrderByModifiedAtDesc(endAt, pageable);
} else if (weather != null && startAt == null) { // 날씨 조건 혹은 endAt으로 조회
todos = todoRepository.findAllByWeather(weather, endAt, pageable);
} else if (weather == null) { // 날짜 조건으로 검색
todos = todoRepository.findAllByDate(startAt, endAt, pageable);
} else { // 날짜와 날씨 조건으로 검색
todos = todoRepository.findAllByWeatherAndDate(weather, startAt, endAt, pageable);
}이 조건문을 따라 실행되는 JPQL 쿼리문과 메서드를 작성한다.
// Repository
@Query("SELECT t FROM Todo t LEFT JOIN FETCH t.user u " +
"WHERE FUNCTION('DATE', t.modifiedAt) <= :endAt " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByOrderByModifiedAtDesc(
@Param("endAt") LocalDate endAt,
Pageable pageable
);
@Query("SELECT t FROM Todo t LEFT JOIN FETCH t.user u " +
"WHERE FUNCTION('DATE', t.modifiedAt) <= :endAt " +
"AND t.weather = :weather " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByWeather(
@Param("weather") String weather,
@Param("endAt") LocalDate endAt,
Pageable pageable
);
@Query("SELECT t FROM Todo t LEFT JOIN FETCH t.user u " +
"WHERE FUNCTION('DATE', t.modifiedAt) BETWEEN :startAt AND :endAt " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByDate(
@Param("startAt") LocalDate startAt,
@Param("endAt") LocalDate endAt,
Pageable pageable
);
@Query("SELECT t FROM Todo t LEFT JOIN FETCH t.user u " +
"WHERE FUNCTION('DATE', t.modifiedAt) BETWEEN :startAt AND :endAt " +
"AND t.weather = :weather " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByWeatherAndDate(
@Param("weather") String weather,
@Param("startAt") LocalDate startAt,
@Param("endAt") LocalDate endAt,
Pageable pageable
);그럼 다음과 같이 일부 또는 수정일의 처음과 끝에 대한 검색 조건을 출력할 수 있다.
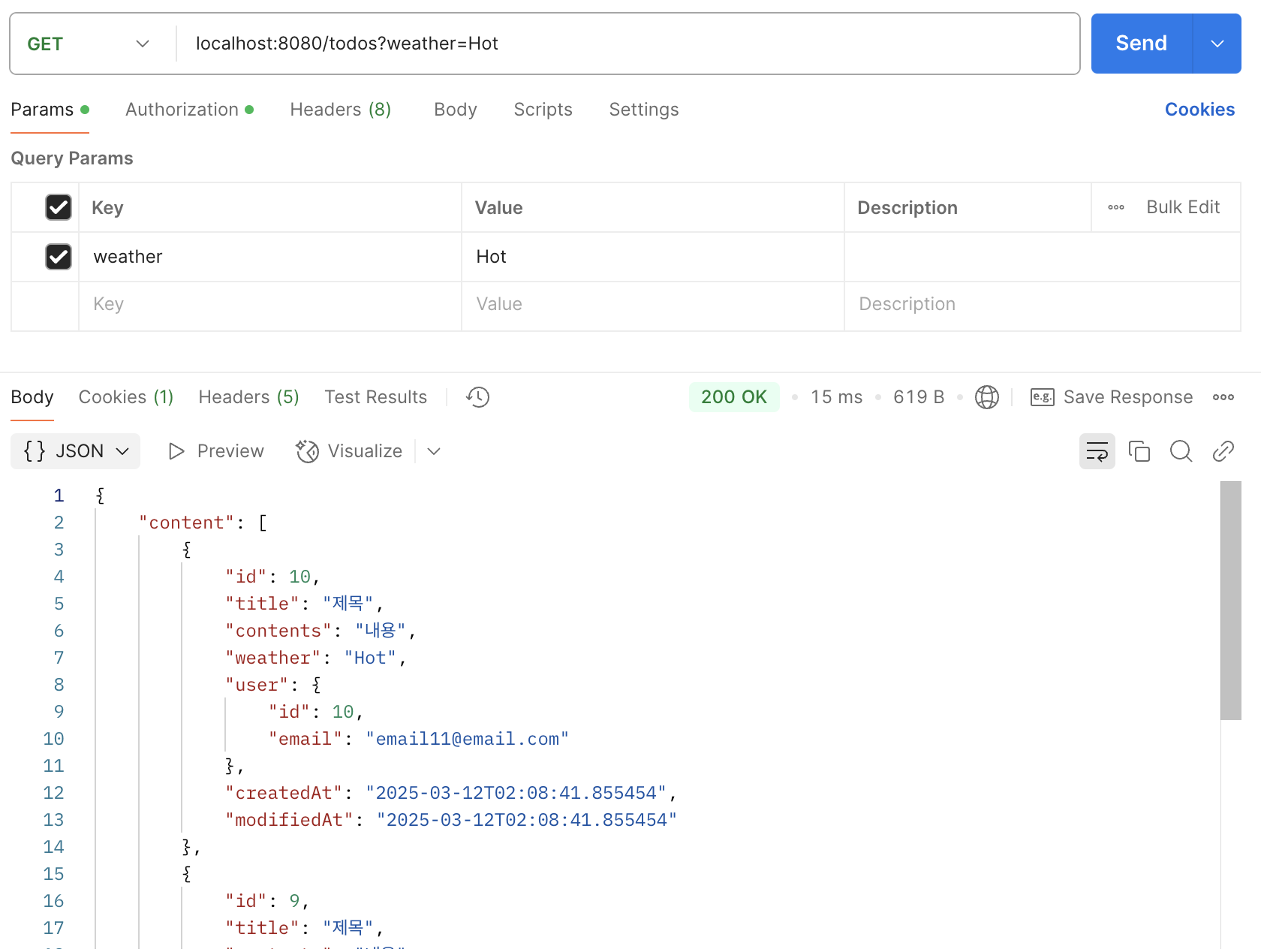
4. Lv.1-4. 테스트 컨트롤러
@Autowired
private MockMvc mockMvc;
@MockBean
private TodoService todoService;
@Test
void todo_단건_조회_시_todo가_존재하지_않아_예외가_발생한다() throws Exception {
// given
long todoId = 1L;
// when
when(todoService.getTodo(todoId))
.thenThrow(new InvalidRequestException("Todo not found"));
// then
mockMvc.perform(get("/todos/{todoId}", todoId))
.andExpect(status().isBadRequest())
.andExpect(jsonPath("$.status").value(HttpStatus.BAD_REQUEST.name()))
.andExpect(jsonPath("$.code").value(HttpStatus.BAD_REQUEST.value()))
.andExpect(jsonPath("$.message").value("Todo not found"));
}컨트롤러의 테스트 코드는 mockMvc를 사용해서 실제 응답에 대해 실제로 응답을 예상한 응답코드와 결과를 남기는 가에 대해 테스트를 한다.(검증을 assertThat() 대신 MockMvc를 사용)
이 경우 실제로 예외를 던지는가에 대한 테스트 코드이므로 예외 출력에 대한 기대를 andExpect에 작성하면 된다.
해당 컨트롤러 메서드가 어떤 service Mock객체를 실행시키는지 when()으로 설정하고,
그 결과를 mockMvc에 작성한다.
이 경우 일정이 아무것도 존재하지 않을때 어떤 (url, method), status, body를 출력하는지 작성한 것이다.
.andExpect()의 jsonPath().value()에는 어떤 json값을 출력하는지 key value 형식으로 작성해준다.

5. Lv.1-5. AOP
포인트 컷 설정의 종류로는 5가지가 있다
- @After: 메서드가 반환되거나 예외 상황이 발생한 이후에 호출(finally)
- @AfterReturning: 메서드가 반환된 이후에 호출(try)
- @AfterThrowing: 메서드가 예외상황을 발생시킨 이후에 호출(catch)
- @Before: 메서드가 호출되기 이전에 호출
- @Around: 메서드의 호출 전과 반환되거나 예외 상황 이후에 호출
이를 이용해 AOP를 수정 하면 다음과 같이 @Before로 수정할 수 있다.
@Before("execution(* org.example.expert.domain.user.controller.UserAdminController.changeUserRole(..))")
public void logAfterChangeUserRole(JoinPoint joinPoint) {
String userId = String.valueOf(request.getAttribute("userId"));
String requestUrl = request.getRequestURI();
LocalDateTime requestTime = LocalDateTime.now();
log.info("Admin Access Log - User ID: {}, Request Time: {}, Request URL: {}, Method: {}",
userId, requestTime, requestUrl, joinPoint.getSignature().getName());
}
6. Lv.2-1. CascadeType.persist
@OneToMany(mappedBy = "todo", cascade = CascadeType.PERSIST)
private List<Manager> managers = new ArrayList<>();Cascade 는 다음과 같은 옵션을 적용할 수 있다.
| CascadeType | 설명 |
| PERSIST | 부모 엔티티를 저장할 때 자식 엔티티도 자동 저장 |
| MERGE | 부모 엔티티를 병합할 때 자식 엔티티도 병합 |
| REMOVE | 부모 엔티티를 삭제하면 자식 엔티티도 삭제 |
| REFRESH | 부모 엔티티를 다시 로드하면 자식 엔티티도 다시 로드 |
| DETACH | 부모 엔티티를 분리하면 자식 엔티티도 분리 |
| ALL | 위의 모든 동작을 포함 |
이중 일정이 저장될때 manager도 자동으로 저장될 수 있도록 하려면 CascadeType.PERSIST를 설정해야한다.
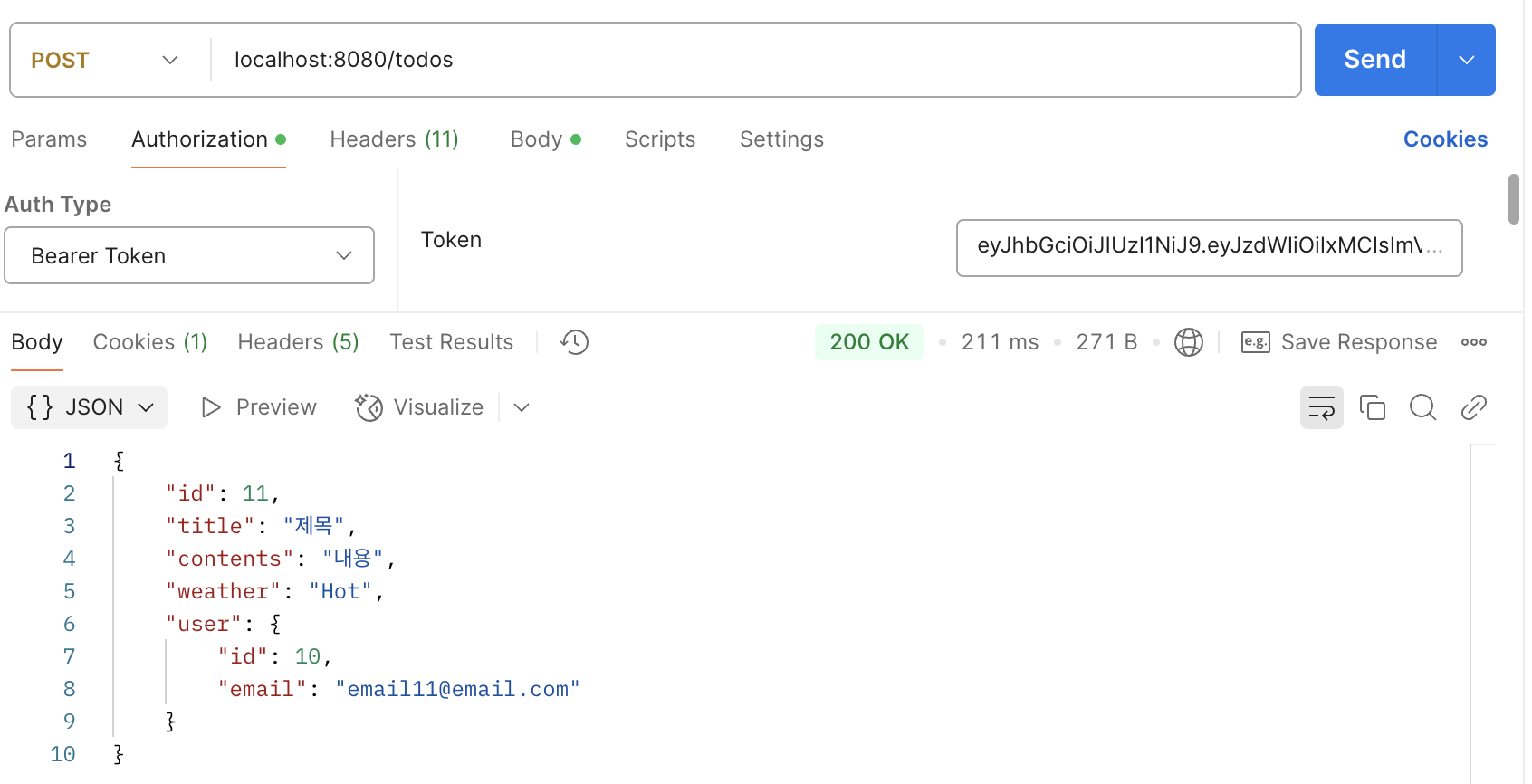
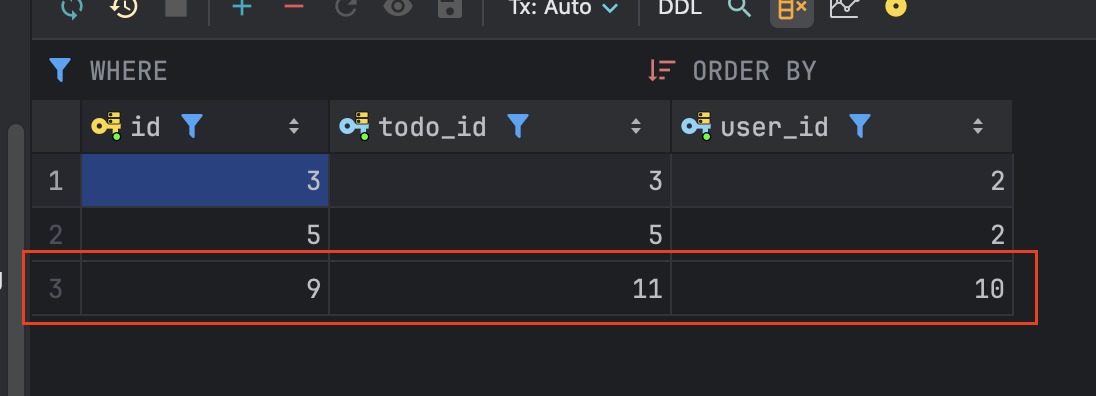
7. Lv2-2. N+1
@Query("SELECT c FROM Comment c JOIN FETCH c.user WHERE c.todo.id = :todoId")
List<Comment> findByTodoIdWithUser(@Param("todoId") Long todoId);N+1 현상이 발생했을 경우 다음과 같은 방법을 사용할 수 있다.
| 해결 방법 | 사용 사례 | 권장 여부 | 주요 특징 | 주의점 |
| JOIN FETCH | 관계가 있는 엔티티를 한 번의 쿼리로 함께 로드할 때 | 매우 추천 | 한 번의 쿼리로 필요한 모든 데이터 로드 | 반환되는 데이터의 양이 많아질 수 있음 |
| 배치 사이즈 설정 | 대량의 연관 데이터를 로드할 때 | 상황에 따라 선택 | N+1 쿼리 수를 줄임, 근본적 해결법은 아니고 그냥 성능 향상법 | 적절한 배치 크기를 설정해야 함 |
| DTO 사용 | 뷰나 API 응답으로 필요한 데이터만 전달할 때 | 매우 추천 | 불필요한 데이터 로드 방지 | 데이터 변환 과정이 필요함 |
| Entity Graphs | 특정 쿼리에서 필드 로드 방식을 제어할 때 | 추천 | 쿼리 세밀 제어 가능 | 복잡한 설정이 필요할 수 있음 |
| FetchType.EAGER | 연관된 엔티티가 항상 필요한 경우 | 권장하지 않음 | 연관 엔티티를 미리 로드하여 지연 없음 | 불필요한 데이터 로드로 성능 저하 가능성 |
이중에 제일 많이 사용하는 join fetch를 사용하여 comment와 user를 함께 가져올 수 있도록 구현하여 문제를 해결했다.
8. Lv2-3. QueryDSL

다음 JPQL로 작성된 코드를 Query DSL로 수정하면 다음과 같다.
@Override
public Optional<Todo> findByIdWithUser(Long todoId) {
return Optional.ofNullable(
jpaQueryFactory.selectFrom(todo)
.leftJoin(todo.user).fetchJoin()
.where(todo.id.eq(todoId))
.fetchFirst()
);
}먼저 Optional로 리턴하고 싶으니 Optional로 Null이 될 수 있는 쿼리를 작성한다.
1️⃣ .selectFrom(): from에 해당하는 테이블을 찾는다. 이때 파라미터는 QClass에서 static으로 가져온 테이블이다.
2️⃣ .leftJoin().fetchJoin(): user를 join fetch()하여 가져완다.
3️⃣ .where(todo.id.eq()): todo.id와 같은 id를 조건으로 한다.
4️⃣ .fetchFirst(): 결과값의 제일 처음을 가져온다. 아무 것도 없을 경우 null을 리턴한다.
9. Lv.2-4. Spring Security
구현 내용은 https://queenriwon3.tistory.com/135 에 상세히 기술해 두었다.
250314 - Java Spring Security: Spring Security의 특징과 구조, JWT를 이용한 Spring Security구현(SecurityContext, Abst
▷ 오늘 배운 것세션으로 배운 Spring Security와 JWT를 활용한 간단한 Spring Security에 대해 작성해보려고 한다. >1. Spring Security 1) Spring Security란? 2) Spring Security의 구조 3) Spring Security 필
queenriwon3.tistory.com
1) 유효하지 않은 UserRole (🚨 트러블 슈팅)
public static User fromAuthUser(AuthUser authUser) {
return new User(authUser.getUserId(), authUser.getEmail(), authUser.getNickname(), UserRole.of(authUser.getAuthorities().toString()));
}처음엔 이렇게 UserRole.of()를 사용하여 생성자를 사용하려고 했다.
public class AuthUser {
private final Long userId;
private final String email;
private final String nickname;
private final Collection<? extends GrantedAuthority> authorities;
public AuthUser(Long userId, String email, String nickname, UserRole role) {
this.userId = userId;
this.email = email;
this.nickname = nickname;
this.authorities = List.of(new SimpleGrantedAuthority(role.name()));
}
}AuthUser의 authorities는 여러 권한을 가질 수 있도록 확장한 형태이기 때문에 어떻게 값을 가져올지 고민이 많았다.
그러나 위의 방법으로 코드를 사용하려고 하면 다음과 같은 응답이 발생한다.
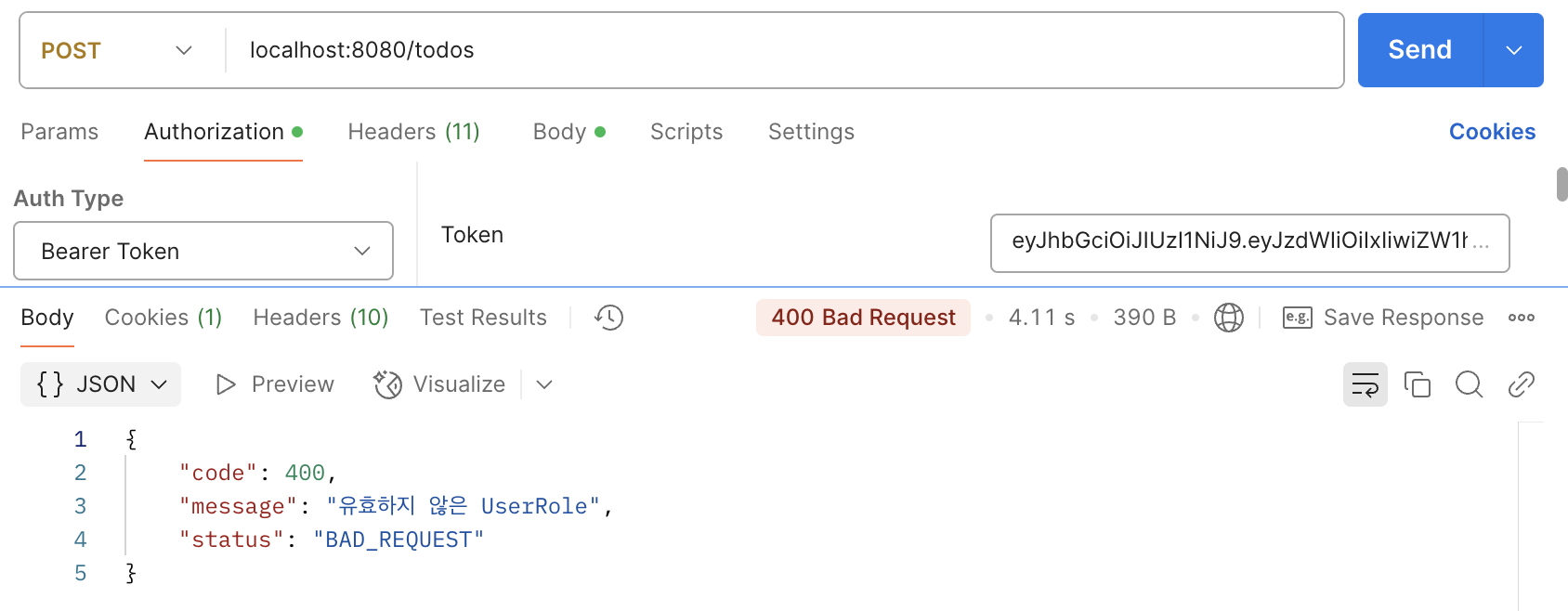
왜 그런지 이유를 디버깅 모드를 이용해보았더니
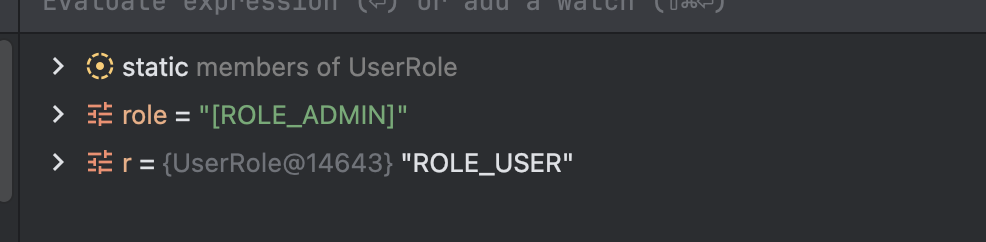
배열의 toString()의 특성상 대괄호가 앞뒤로 붙어서 나온다는 것을 확인할 수 있었다.
그럼 배열안의 값을 문자열의 형태로 가져올 수 있어야 한다.
배열안의 값을 가져오기 위해서 다음과 같은 메서드를 AuthUser에 구현하기로 했다.
public UserRole getUserRole() {
return authorities.stream()
.map(GrantedAuthority::getAuthority)
.map(UserRole::valueOf)
.findFirst()
.orElseThrow(() -> new IllegalArgumentException("No role found"));
}authorities안의 배열값을 가져오기 위해서 stream()의 map()으로 getAuthority을 가져오고 enum값을 가져오는 방법으로 배열의 첫번째 것을 유저의 권한으로 설정한다.
현재는 코드 전체적으로 권한이 두개 밖에 없기 때문에 하나의 권한만 꺼내 비교하는 코드로 작성 해보았다.
권한을 여러개로 확장하고 싶을때 어떻게 코드를 수정할 수 있을지 고민해봐야겠다는 생각이 들었다.
+
여기서 AuthUser는 엔티티 이기때문에 엔티티에서 예외를 발생시키는 것 자체가 책임 분리가 되지 않는 다는 생각을 했다.
따라서 UserRole에 대한 예외는 UserRole만 알 수 있도록 관련 메서드를 옮겨보고자 했다.
public static User fromAuthUser(AuthUser authUser) {
return new User(authUser.getUserId(), authUser.getEmail(), authUser.getEmail(),
UserRole.of(authUser.getAuthorities().iterator().next().getAuthority()));
}따라서 다음과 같은 메서드를 만들었고,
public static UserRole of(String role) {
return Arrays.stream(UserRole.values())
.filter(r -> r.getUserRole().equalsIgnoreCase(role))
.findFirst()
.orElseThrow(() -> new InvalidRequestException("유효하지 않은 UserRole"));
}이를 이용할 수 있는 메서드를 UserRole에서 생성했다.
2) 테스트 코드 (🚨 트러블 슈팅)
Controller에 spring security를 적용하면 테스트 코드에 다음과 같은 에러가 발생하게 된다.
Failed to load ApplicationContext for [WebMergedContextConfiguration@6009cd34 testClass = org.example.expert.domain.todo.controller.TodoControllerTest, locations = [], classes = [org.example.expert.ExpertApplication], contextInitializerClasses = [], activeProfiles = [], propertySourceDescriptors = [], propertySourceProperties = ["org.springframework.boot.test.autoconfigure.web.servlet.WebMvcTestContextBootstrapper=true"], contextCustomizers = [org.springframework.boot.test.autoconfigure.OverrideAutoConfigurationContextCustomizerFactory$DisableAutoConfigurationContextCustomizer@23bff419, ...
컨트롤러 테스트 코드를 수정하는 방법은 4가지가 된다.
https://github.com/Nhahan/stateless-spring-security
GitHub - Nhahan/stateless-spring-security: stateless-spring-security
stateless-spring-security. Contribute to Nhahan/stateless-spring-security development by creating an account on GitHub.
github.com
1️⃣ 기본 인증 토큰 주입 방식
각 테스트 메서드마다 JwtAuthenticationToken을 생성하여 인증 객체를 직접 주입하는 방법
@Test
public void 권한이_ADMIN일_경우_200() throws Exception {
AuthUser authUser = new AuthUser(1L, "admin@example.com", UserRole.ROLE_ADMIN);
JwtAuthenticationToken authenticationToken = new JwtAuthenticationToken(authUser); // JwtAuthenticationToken 생성으로 테스트
mockMvc.perform(get("/test")
.with(authentication(authenticationToken)))
.andExpect(status().isOk());
}
2️⃣ 사전 설정된 토큰 재사용 방식
@BeforeEach를 사용하여 테스트 실행 전에 인증 토큰을 미리 생성하고 재사용하는 방식
@BeforeEach
public void setUp() { // 상황에 맞는 인증토큰을 미리 set
AuthUser adminUser = new AuthUser(1L, "admin@example.com", UserRole.ROLE_ADMIN);
adminAuthenticationToken = new JwtAuthenticationToken(adminUser);
AuthUser normalUser = new AuthUser(2L, "user@example.com", UserRole.ROLE_USER);
userAuthenticationToken = new JwtAuthenticationToken(normalUser);
}
@Test
public void 권한이_ADMIN일_경우_200() throws Exception {
mockMvc.perform(get("/test")
.with(authentication(adminAuthenticationToken)))
.andExpect(status().isOk());
}
3️⃣ 커스텀 어노테이션 방식
커스텀 어노테이션을 생성하여 테스트 메서드에 직접 인증 정보를 설정하는 방식
@Test
@WithMockAuthUser(userId = 1L, email = "admin@example.com", role = UserRole.ROLE_ADMIN)
public void 권한이_ADMIN일_경우_200() throws Exception {
mockMvc.perform(get("/test"))
.andExpect(status().isOk());
}
@Retention(RetentionPolicy.RUNTIME)
@WithSecurityContext(factory = TestSecurityContextFactory.class)
public @interface WithMockAuthUser {
long userId();
String email();
UserRole role();
}
// WithSecurityContext에 사용된 클래스(인증토큰을 SecurityContextHolder에 적용)
public class TestSecurityContextFactory implements WithSecurityContextFactory<WithMockAuthUser> {
@Override
public SecurityContext createSecurityContext(WithMockAuthUser customUser) {
SecurityContext context = SecurityContextHolder.createEmptyContext();
AuthUser authUser = new AuthUser(customUser.userId(), customUser.email(), customUser.role());
JwtAuthenticationToken authentication = new JwtAuthenticationToken(authUser);
context.setAuthentication(authentication);
return context;
}
}
4️⃣ @WithMockUser을 사용하는 방법
https://sasca37.tistory.com/291
[Spring Security] @WithMockUser, @WithAnonymousUser, @WithUserDetails
@WithMockUser @WithMockUser 어노테이션은 Controller 테스트 시에 Spring Security에 설정한 인증 정보를 제공해 주는 역할을 합니다. 정확히는 사용자 인증 정보를 담은 Authentication을 UsernamePasswordAuthenticationTo
sasca37.tistory.com
@WithMockUser@WithMockUser은 간단하게 인증된 사용자를 만들지 않아도 테스트를 요청할 수 있는 어노테이션이다.
기본적으로 username = "user", role = "USER" 인 사용자가 만들어진다.
@WithAnonymousUser반대로 @WithAnonymousUser을 사용하면 인증되지 않은 사용자를 만들어서 사용해 준다.
현재는 유저정보를 userId, email, nickname, userRole을 사용하기 때문에 username과 role만 있는 @WithMockUser를 사용하기에는 적합하지 않다고 생각했으나, mock객체로 사용하므로 크게 신경쓰지 않아도 된다고 생각했다.
그래서 테스트 코드에는 @WithMockUser를 사용했다.
10. Lv.3-1. QueryDSL 을 사용하여 검색 기능
다양한 검색기능을 구현해야하기 때문에, QueryDSL과 동적쿼리를 합쳐야한다.
그리고 Projections사용을 권장하고 있기때문에, Projections의 방법도 함께 알아보아야겠다고 생각했다.
1) QueryDSL 의 동적쿼리
https://velog.io/@eunhye_/Querydsl-%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
Querydsl? 동적쿼리?
QueryDsl은 정적 타입을 이용해서 SQL과 같은 쿼리를 생성할 수 있도록 해주는 프레임워크이다.
velog.io
동적쿼리는 다음 블로그를 참고하여
1️⃣ BooleanBuilder를 사용했다.
BooleanBuilder builder = new BooleanBuilder();이 builder인스턴스에서 쿼리를 쌓는 방법을 통해 쿼리의 .where(builder)에 적용할 수 있다.
2️⃣ BooleanExpression 방법도 존재하는데,
private BooleanExpression nameEq(String nameCond) {
if (nameCond == null) {
return null;
}
return member.name.eq(nameCond);
}동적쿼리 조건문을 하나의 메서드로 만들어서 BooleanExpression 형태로 반환하는 방식을 사용한다.
메서드로 만들었기 때문에 재사용성이 좋다는 장점이 있다.(유지보수성이 높다)
2) Projection
[QueryDSL] Projections(Dto 조회)와 @QueryProjection
Projections(Dto 조회)와 @QueryProjection 특정 Entity를 조회할 때 Entity의 모든 값들이 필요하지 않은 경우가 있습니다. 예를 들면 게시판 목록을 보여줄 때 게시판의 내용(contents)이 필요하지 않고, 게시
j-dong.tistory.com
프로젝션은 다음블로그를 참고했다.
DB의 모든 필드를 가져오는 것은 불필요한 자원낭비가 되어 성능이 저하되는 원인이 되기도 한다.
이러한 문제를 해결하기 위해 QueryDSL에서는 불필요한 값들은 조회하지 않고, 필요한 값들만 조회할 수 있도록 성능을 최적화시켜 주는 Projections을 제공한다.
프로젝션을 적용하는 방법은 여러가지가 있다.
1️⃣ Projections.bean(..)
setter와 기본생성자가 필요하다
TodoGetResponse todoGetResponse = queryFactory
.select(Projections.bean(TodoGetResponse.class,
todo.id,
todo.title,
...
))
.from(todo)
2️⃣ Projections.field(..)
필드명으로 매핑되기 때문에 Dto 객체를 불변 객체로 사용 가능
TodoGetResponse todoGetResponse = queryFactory
.select(Projections.fields(TodoGetResponse.class,
todo.id,
todo.title,
...
))
.from(todo)
3️⃣ Projections.construct(..)
@AllArgsConstructor 필요
TodoGetResponse todoGetResponse = queryFactory
.select(Projections.construct(TodoGetResponse.class,
todo.id,
todo.title,
...
))
.from(todo)
4️⃣ @QueryProjection
컴파일 시점에서 에러를 잡아낼 수 있음
@QueryProjection // TodoGetResponse 인덱스 클래스 생성자
public TodoGetResponse(Long id, String title, ...) {
this.id = id;
this.title = title;
...
}TodoGetResponse todoGetResponse = queryFactory
.select(new TodoGetResponse(
todo.id,
todo.title,
...
))
.from(todo)
3) group by사용 하여 구현
https://heekng.tistory.com/166
[QueryDSL] 페이징 연동하기
페이징 연동하기 Spring Data JPA에서 Page와 Pageable을 이용하고, QueryDSL을 이용하여 페이징을 사용해보자. 가장 효율적인 방법 이전까지의 페이징 방법중 하나는 fetchCount()와 fetchResult()를 이용하는 방
heekng.tistory.com
@Override
public Page<TodoGetResponse> findByTitleOrCreatedAtOrManager(
String title,
LocalDate startAt,
LocalDate endAt,
String managerName,
Pageable pageable) {
BooleanBuilder builder = new BooleanBuilder();
if (title != null) {
builder.and(todo.title.contains(title));
}
if (startAt != null) {
builder.and(todo.createdAt.goe(startAt.atStartOfDay()));
}
if (endAt != null) {
builder.and(todo.createdAt.loe(endAt.atStartOfDay()));
}
if (managerName != null) {
builder.and(manager.user.nickname.contains(managerName));
}
List<TodoGetResponse> todoGetResponseList = jpaQueryFactory
.select(
Projections.constructor(
TodoGetResponse.class,
todo.title,
manager.countDistinct(),
comment.countDistinct()
)
)
.from(todo)
.leftJoin(manager).on(manager.todo.id.eq(todo.id))
.leftJoin(comment).on(comment.todo.id.eq(todo.id))
.where(builder)
.groupBy(todo.id, todo.title)
.orderBy(todo.createdAt.desc())
.offset(pageable.getOffset()).limit(pageable.getPageSize()).fetch();
// 페이징에 이용되는 갯수 출력
JPAQuery<Long> countQuery = jpaQueryFactory
.select(todo.count())
.from(todo)
.where(builder);
return PageableExecutionUtils.getPage(todoGetResponseList, pageable, countQuery::fetchOne);
}manager의 수와 comment의 수를 출력하기 위해서 todo에 대한 groupby를 해준다.
이때 .countDistict()를 해주는 이유는 join을 하면서 중복된 갯수가 생길 수 있기 때문이다.
그리고 페이징을 사용할때 PageableExecutionUtils.getPage()을 사용했는데, PageImpl을 사용하지 않은 이유는 마지막또는 처음 페이지에 대한 쿼리문을 작성할 때, 동작을 한번 덜하는 성능적인 이점이 있기 때문이다.
따라서 PageableExecutionUtils.getPage()을 사용하는 것이 성능상 효율이 좋다.
https://code-list.tistory.com/102
QueryDsl 페이징 최적화 PageImpl vs PageableExecutionUtils 차이
PageImpl vs PageableExecutionUtils return PageableExecutionUtils.getPage(result, pageable, countQuery::fetchOne); return new PageImpl(result, pageable, count); 둘의 차이는 무엇일까? 상황 예시 24개의 content가 존재한다고 가정해보자
code-list.tistory.com
4) 서브쿼리 사용 (🚨 트러블 슈팅)
https://wildeveloperetrain.tistory.com/174
Querydsl 서브쿼리 사용하는 방법(select절, where절)
'Querydsl 서브 쿼리 사용법'에 대해 간단하게 정리한 내용입니다. Querydsl이 나오게 된 배경을 살펴보고 이어서 subquery를 적용하는 코드 예시가 있는데요. Querydsl의 경우 다른 것 보다 사용하기 위한
wildeveloperetrain.tistory.com
여기서 튜터님이 groupby를 사용하는 것 보다 서브 쿼리를 사용하는 것이 더 성능상좋다고 조언해주셨다. 그래서 위의 코드를 서브쿼리로 변경해서 적용시켜 줄 것이다.
서브 쿼리는 JPAExpressions.select()을 사용하여 작성할 수 있으며, 여기서 join을 해줄 필요가 없어진다.
// 2. 서브쿼리 사용 (groupby 및 join 생략 가능)
List<TodoGetResponse> todoGetResponseList = jpaQueryFactory
.select(
Projections.constructor(
TodoGetResponse.class,
todo.title,
JPAExpressions.select(manager.countDistinct())
.from(manager)
.where(manager.todo.id.eq(todo.id)),
JPAExpressions.select(comment.countDistinct())
.from(comment)
.where(comment.todo.id.eq(todo.id))
)
)
.from(todo)
.where(builder)
.orderBy(todo.createdAt.desc())
.offset(pageable.getOffset()).limit(pageable.getPageSize())
.fetch();
그런데 조건문 외의 쿼리부분만 작성해주었더니 다음과 같은 에러가 발생했다.
org.hibernate.query.SemanticException: Could not interpret path expression 'manager.user.nickname' at org.hibernate.query.hql.internal.BasicDotIdentifierConsumer$BaseLocalSequencePart.resolvePathPart(BasicDotIdentifierConsumer.java:241) ~[hibernate-core-6.5.2.Final.jar:6.5.2.Final] at org.hibernate.query.hql.internal.BasicDotIdentifierConsumer.consumeIdentifier(BasicDotIdentifierConsumer.java:92) ~[hibernate-core-6.5.2.Final.jar:6.5.2.Final] at org.hibernate.query.hql.internal.SemanticQueryBuilder.visitSimplePath(SemanticQueryBuilder.java:5269) ~[hibernate-core-6.5.2.Final.jar:6.5.2.Final] at
...
이 에러는 조건문에 작성해준 manager를 from 또는 join에서 찾을 수 없기때문에 발생한 에러이다.
따라서 이부분또한 서브쿼리로 작성해주어 생략한 join 부분을 서브쿼리로 작성해주어야 한다는 것이다.
그래서 다음과 같이 조건문을 변경할 수 있었다.
if (managerName != null) {
builder.and(
JPAExpressions.selectOne()
.from(manager)
.where(
manager.todo.id.eq(todo.id),
manager.user.nickname.contains(managerName)
)
.exists()
);
}
// 2. 서브쿼리 사용 (groupby 및 join 생략 가능)
List<TodoGetResponse> todoGetResponseList = jpaQueryFactory
.select(
Projections.constructor(
TodoGetResponse.class,
todo.title,
JPAExpressions.select(manager.countDistinct())
.from(manager)
.where(manager.todo.id.eq(todo.id)),
JPAExpressions.select(comment.countDistinct())
.from(comment)
.where(comment.todo.id.eq(todo.id))
)
)
.from(todo)
.where(builder)
.orderBy(todo.createdAt.desc())
.offset(pageable.getOffset()).limit(pageable.getPageSize())
.fetch();
JPAQuery<Long> countQuery = jpaQueryFactory
.select(todo.count())
.from(todo)
.where(builder);
return PageableExecutionUtils.getPage(todoGetResponseList, pageable, countQuery::fetchOne);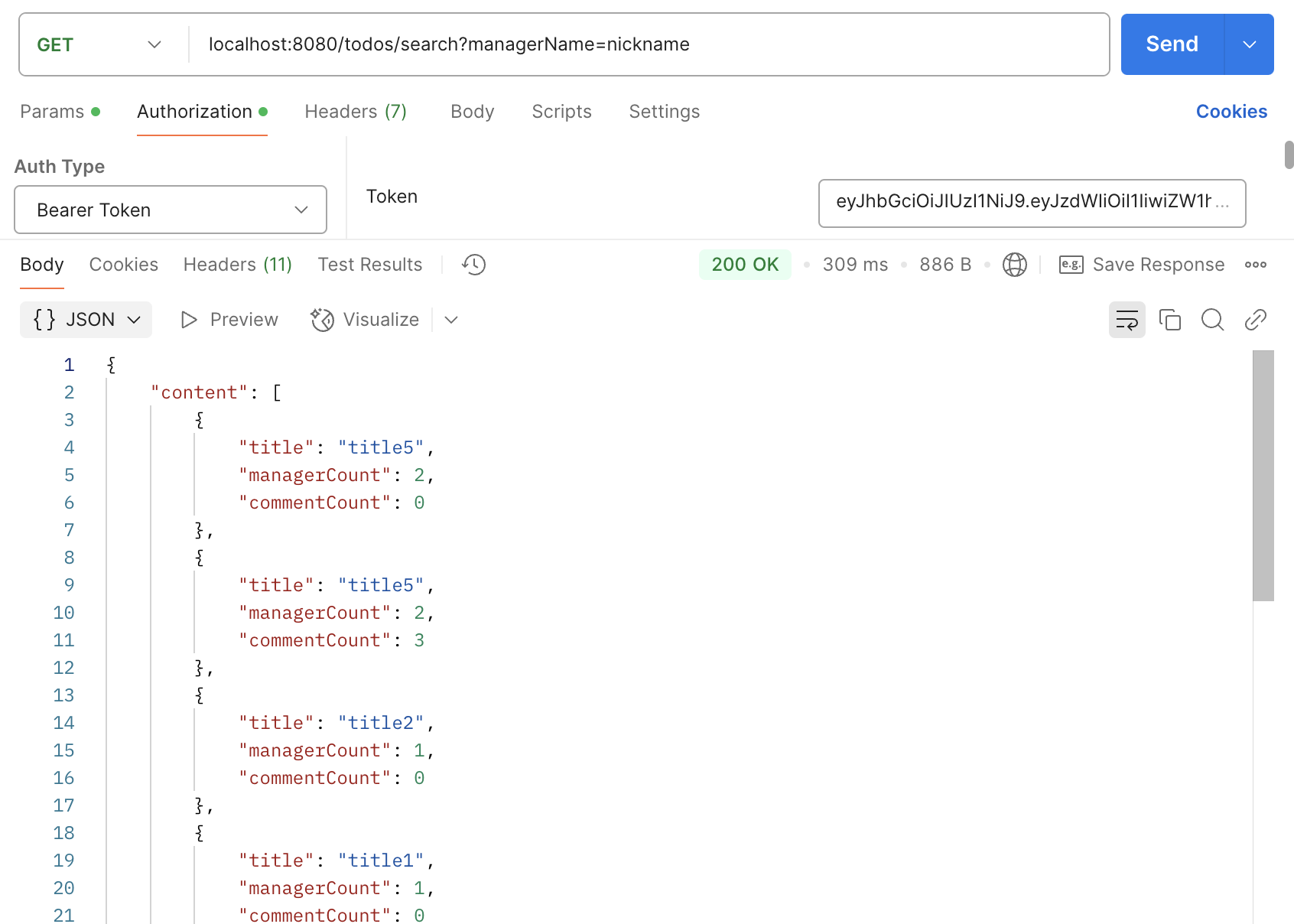
11. Lv.3-2. Propagation.REQUIRES_NEW를 이용하여 요청로그 저장
트랜잭션의 Propagation이란, 트랜잭션이 다른 트랜잭션과 어떻게 상호작용할지를 결정하는 방식이다.
종류
- REQUIRED (기본값): 이미 진행 중인 트랜잭션이 있으면 그 트랜잭션을 사용하고, 없으면 새 트랜잭션을 시작
- REQUIRES_NEW: 항상 새 트랜잭션을 시작하며, 진행 중인 트랜잭션은 잠시 중단(로그를 작성할 때 주로 사용. 에러가 발생해도 로그를 작성할 수 있음)
- SUPPORTS: 트랜잭션이 이미 존재하면 그 트랜잭션 내에서 실행하고, 없으면 비트랜잭션 실행
- MANDATORY: 현재 트랜잭션이 반드시 있어야 하며, 없으면 예외가 발생
- NEVER: 트랜잭션 없이 실행되어야 하며, 트랜잭션이 존재하면 예외가 발생
- NESTED: 진행 중인 트랜잭션 내부에 또 다른 트랜잭션을 중첩시켜 실행할 수 있으며, 이 경우 Savepoint를 이용
이렇게 많은 종류 중에서 에러가 발생해도 독립적인 트랜잭션으로 동작할 수 있도록 하는 REQUIRES_NEW을 사용해보도록 하겠다.
일단 요청로그를 저장하는 엔티티 클래스를 작성해준다.
내용은 추적할 id, url, 요청시간, 메서드, 요청바디를 저장해줄 것이다.
@Entity
@Getter
@NoArgsConstructor
public class Log {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String traceId;
private String url;
private LocalDateTime requestTime;
private String method;
private String body;
// 요청
public Log(String url, String method, String body) {
this.traceId = UUID.randomUUID().toString().substring(0, 8);
this.url = url;
this.requestTime = LocalDateTime.now();
this.method = method;
this.body = body;
}
}
그래서 다음과 같은 로그서비스를 작성해서 서비스에서 호출할 수 있도록 구현했다.
여기서 요청로그를 작성하는 메서드는 @Transactional(propagation = Propagation.REQUIRES_NEW)로 작성해주었다.
@Service
@RequiredArgsConstructor
public class LogService {
private final LogRepository logRepository;
private final HttpServletRequest request;
private final ObjectMapper objectMapper;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public <T> void loggingRequest(T requestBody) throws JsonProcessingException {
logRepository.save(new Log(
request.getRequestURI(),
request.getMethod(),
objectMapper.writeValueAsString(requestBody)));
}
}
그럼 다음과 같이 로그가 저장되게된다. 만약 API 메서드 동작시 에러가 난다고 해도 트랜잭션이 독립적으로 동작하기때문에 로그는 언제나 정상적으로 찍히게 된다.

요청뿐만이 아닌 성공과 실패에 따른 성공 로그도 함께 작성하고 싶었는데,
이럴 경우 AOP를 사용하여 @Around 어노테이션을 사용, 횡단 관심사를 분리하여 로그를 작성하는 것이 제일 좋을 것 같다고 판단했다.
따라서 이번 과제는 Propagation.REQUIRES_NEW를 사용하는 것이었으므로, 요청로그에서 마무리하려고 한다.


