이지은님의 블로그
250310 - 동기와 비동기, 블로킹과 언블로킹, 데이터베이스 활용 개념 정리(Sync vs Async & Blocking vs Non-Blocking, Server/In-memory/Embedded Mode) 본문
250310 - 동기와 비동기, 블로킹과 언블로킹, 데이터베이스 활용 개념 정리(Sync vs Async & Blocking vs Non-Blocking, Server/In-memory/Embedded Mode)
queenriwon3 2025. 3. 11. 01:30▷ 오늘 배운 것
세션과 JPA 심화공부를 하면서 몰랐던 부분을 따로 정리하고자 한다.
<<목차>>
1. 동기/비동기와 블로킹/논블로킹
1) 동기(Synchronous) vs 비동기(Asynchronous)
2) Blocking vs Non-Blocking
3) Sync vs Async & Blocking vs Non-Blocking 차이
2. 동시성과 병렬성
1) 동시성(Concurrency) vs 병렬성(Parallelism)
2) 적용사례
3. DB의 사용방식(H2 기준)
1) Server Mode
2) In-memory Mode
3) Embedded Mode
4. 데이터베이스 Driver
1) 데이터베이스 Driver 역할 및 종류
2) 데이터베이스 Driver 동작
1. 동기/비동기와 블로킹/논블로킹
1) 동기(Synchronous) vs 비동기(Asynchronous)

1️⃣ 동기(Synchronous, Sync)
- 한 작업이 완료될 때까지 대기한 후 다음 작업을 수행하는 방식
- 순차적으로 실행되므로 코드의 실행 흐름을 예측하기 쉽지만, 속도가 느릴 수 있음
- 특정 작업이 오래 걸릴 경우 다른 작업이 블로킹(Blocking)됨
2️⃣ 비동기(Asynchronous, Async)
- 한 작업을 실행하는 동안 다른 작업을 동시에 수행 가능
- 시간이 오래 걸리는 작업(예: API 호출, 데이터베이스 조회, 파일 처리)을 비동기로 처리하면 성능이 향상됨
- Java에서는 @Async, CompletableFuture, ExecutorService, Reactor(WebFlux) 등을 이용하여 비동기 처리 가능
@Service
public class AsyncService {
@Async // 별도 스레드에서 실행됨(비동기스레드)
public CompletableFuture<String> fetchDataAsync() {
try {
Thread.sleep(3000); // 3초 대기
} catch (InterruptedException e) {
e.printStackTrace();
}
return CompletableFuture.completedFuture("비동기 처리 완료"); // 비동기 스레드가 실행된 후 완료 출력
}
}
@RestController
@RequestMapping("/api")
public class AsyncController {
...
@GetMapping("/async")
public CompletableFuture<String> getAsyncData() {
System.out.println("비동기 요청 시작"); //로거 그냥 안씀
CompletableFuture<String> future = asyncService.fetchDataAsync();
System.out.println("비동기 요청 종료");
return future;
}
}
// 비동기 요청 시작
// 비동기 요청 종료
// 비동기 처리 완료
3️⃣ 동기와 비동기 방식의 비교
| 비교 항목 | 동기 | 비동기 |
| 작업 처리 방식 | 순차적으로 실행 | 동시에 여러 작업 가능 |
| 응답 대기 여부 | 요청이 끝날 때까지 대기 | 결과를 기다리지 않고 즉시 다음 코드 실행 |
| 성능 | 속도가 상대적으로 느림 | 대규모 트래픽에서 성능 향상 |
| 사용 방식 | 일반 메서드 호출 | @Async, CompletableFuture, ExecutorService |
| 적용 예제 | CRUD, 데이터 조회 | 대량 데이터 처리, 비동기 API |
2) Blocking vs Non-Blocking
1️⃣ Blocking (블로킹)
- 작업을 수행할 때 결과가 나올 때까지 현재 스레드가 멈춰있는 방식
- 요청을 보낸 스레드는 결과를 받을 때까지 아무 작업도 하지 못하고 기다림
사용방법) Java의 InputStream.read(), JDBC (전통적인 DB 연동)
public class BlockingIOExample {
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("data.txt"))) {
String line = reader.readLine(); // 파일 읽기 작업이 끝날 때까지 블로킹됨
System.out.println("읽은 데이터: " + line);
} catch (IOException e) {
e.printStackTrace();
}
}
}
// (파일을 읽을 때까지 프로그램이 멈춰있음)
// 읽은 데이터: Hello World
2️⃣ Non-Blocking (논블로킹)
- 작업을 요청한 후, 즉시 제어권을 반환하고 다른 작업을 수행할 수 있는 방식
- 요청을 보낸 스레드는 응답을 기다리지 않고 다른 작업을 수행 가능
사용방법) Java NIO (Non-blocking I/O), WebFlux, Netty
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.CompletableFuture;
public class NonBlockingIOExample {
public static void main(String[] args) {
System.out.println("파일 읽기 시작");
// 비동기
CompletableFuture.supplyAsync(() -> {
try {
return Files.readString(Path.of("data.txt"), StandardCharsets.UTF_8);
} catch (Exception e) {
e.printStackTrace();
return "";
}
}).thenAccept(content -> System.out.println("읽은 데이터: " + content));
// .thenAccept(): try-catch구문이후 실행됨
System.out.println("다른 작업 수행 중...");
}
}
// 파일 읽기 시작
// 다른 작업 수행 중...
// 읽은 데이터: Hello World| 비교 항목 | Blocking | Non-Blocking |
| 작업 처리 방식 | 요청을 보낸 후 응답이 올 때까지 대기 | 요청을 보낸 후 즉시 다음 작업 수행 가능, 유연한 스레드 진행 |
| 예제 | InputStream.read(), JDBC | Java NIO, CompletableFuture |
| 스레드 효율 | 하나의 요청이 하나의 스레드를 점유 | 하나의 스레드가 여러 요청을 처리 가능 |
| 적용 예시 | 일반적인 파일 I/O, JDBC 연결 | WebFlux, Netty 기반 웹 서버 |
| 장점 | 코드가 직관적이고 이해하기 쉬움 | 성능 향상 (특히 대량 요청 처리 시 유리) |
| 단점 | 응답 대기 시간이 길어지면 성능 저하 | 코드가 복잡해질 수 있음 |
3) Sync vs Async & Blocking vs Non-Blocking 차이
| 개념 | Sync | Async | Blocking | Non-Blocking |
| 작업 방식 | 요청을 보낸 후 결과를 기다림 | 요청을 보낸 후 결과를 기다리지 않음 | 작업 완료까지 스레드가 멈춤 | 작업이 끝나지 않아도 바로 반환 |
| 스레드 활용 | 요청마다 스레드 점유 | 하나의 스레드가 여러 작업 처리 가능 | 하나의 작업이 끝날 때까지 다른 작업 수행 불가 | 하나의 스레드가 여러 작업을 수행 가능 |
| 대표적인 방식 | 일반적인 함수 호출,CRUD | @Async, CompletableFuture | Thread.sleep(), InputStream.read() | Java NIO, WebFlux, Netty |
| 예제 | fetchData()후 대기 | fetchDataAsync() 후 다른 작업 수행 | readFileBlocking() | readFileNonBlocking() |
Blocking vs Non-Blocking은 "작업이 완료될 때까지 기다리는가?"의 차이
- Blocking → 스레드가 멈춰서 기다림
- Non-Blocking → 스레드가 기다리지 않고 다른 작업 수행 가능
Sync vs Async는 "작업이 순차적으로 실행되는가?"의 차이
- Sync → 이전 작업이 끝나야 다음 작업 시작
- Async → 여러 작업을 동시에 진행 가능
2. 동시성과 병렬성
1) 동시성(Concurrency) vs 병렬성(Parallelism)
1️⃣ 동시성(Concurrency)
- 하나의 CPU(코어)에서 여러 작업을 번갈아가며 실행하는 방식
- 실제로 같은 순간에 여러 작업이 실행되는 것이 아니라 작업 간 전환(Context Switching)을 통해 빠르게 수행되는 것처럼 보임
- 멀티스레드(Multi-threading), 비동기(Async) 프로그래밍과 관련됨
public class ConcurrencyExample {
public static void main(String[] args) {
Runnable task1 = () -> {
for (int i = 0; i < 5; i++) {
System.out.println("Task 1 실행 중...");
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
}
};
Runnable task2 = () -> {
for (int i = 0; i < 5; i++) {
System.out.println("Task 2 실행 중...");
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
}
};
new Thread(task1).start();
new Thread(task2).start();
}
}
번갈아가면서 실행됨
Task 1 실행 중...
Task 2 실행 중...
Task 1 실행 중...
Task 2 실행 중...
...
2️⃣ 병렬성(Parallelism)
- 여러 개의 CPU(멀티코어)를 활용하여 여러 작업을 완전히 동시에 실행하는 방식
- 멀티코어 시스템에서 각 작업이 독립적으로 실행되며 속도가 크게 향상됨
- 멀티프로세싱(Multi-processing), 병렬 스트림(Parallel Streams), ForkJoinPool과 관련됨
public class ParallelExample {
public static void main(String[] args) {
IntStream.range(1, 10).parallel().forEach(i ->
System.out.println(Thread.currentThread().getName() + " - Task " + i)
);
}
}
ForkJoinPool.commonPool-worker-1 - Task 2
ForkJoinPool.commonPool-worker-2 - Task 3
ForkJoinPool.commonPool-worker-3 - Task 1
ForkJoinPool.commonPool-worker-1 - Task 4
...
3️⃣ 동시성(Concurrency) vs 병렬성(Parallelism) 차이점
동시성(Concurrency) vs 병렬성(Parallelism) 차이
| 비교 항목 | 동시성(Concurrency) | 병렬성(Parallelism) |
| 개념 | 여러 작업을 번갈아 실행 (스레드 전환) | 여러 작업을 완전히 동시에 실행 |
| CPU 개수 | 단일 CPU에서도 가능 | 멀티코어 CPU 필요 |
| 작업 방식 | 여러 작업을 빠르게 스위칭하여 처리 | 여러 작업을 동시에 실행 |
| 적용 기술 | 멀티스레딩, 비동기 처리 | 멀티프로세싱, 병렬 연산 |
| 장점 | 하나의 CPU로도 다중 작업 가능 | 성능 최적화, 대량 데이터 병렬 처리 |
| 단점 | 스레드 전환 오버헤드 발생 | 멀티코어 환경에서만 효과적, 비쌈 |
| 예제 | 웹 서버의 요청 처리, 비동기 이벤트 루프 | 머신러닝 연산, 대량 데이터 처리 |
| 정리 | => 실제로는 한 번에 하나의 작업만 실행되지만, 빠른 전환(Context Switching)으로 여러 작업이 동시에 실행되는 것처럼 보이는 것 | => 실제로 여러 개의 작업이 동시에 실행됨 |
2) 적용사례
1️⃣ 동시성이 필요한 경우
- 웹 서버 요청 처리 (Spring MVC): HTTP 요청이 많을 때 멀티스레드를 사용하여 여러 요청을 동시 처리
- 게임 캐릭터 행동
2️⃣ 병렬성이 필요한 경우
- 머신러닝 모델 학습
- 비디오 렌더링
3. DB의 사용방식(H2 기준)
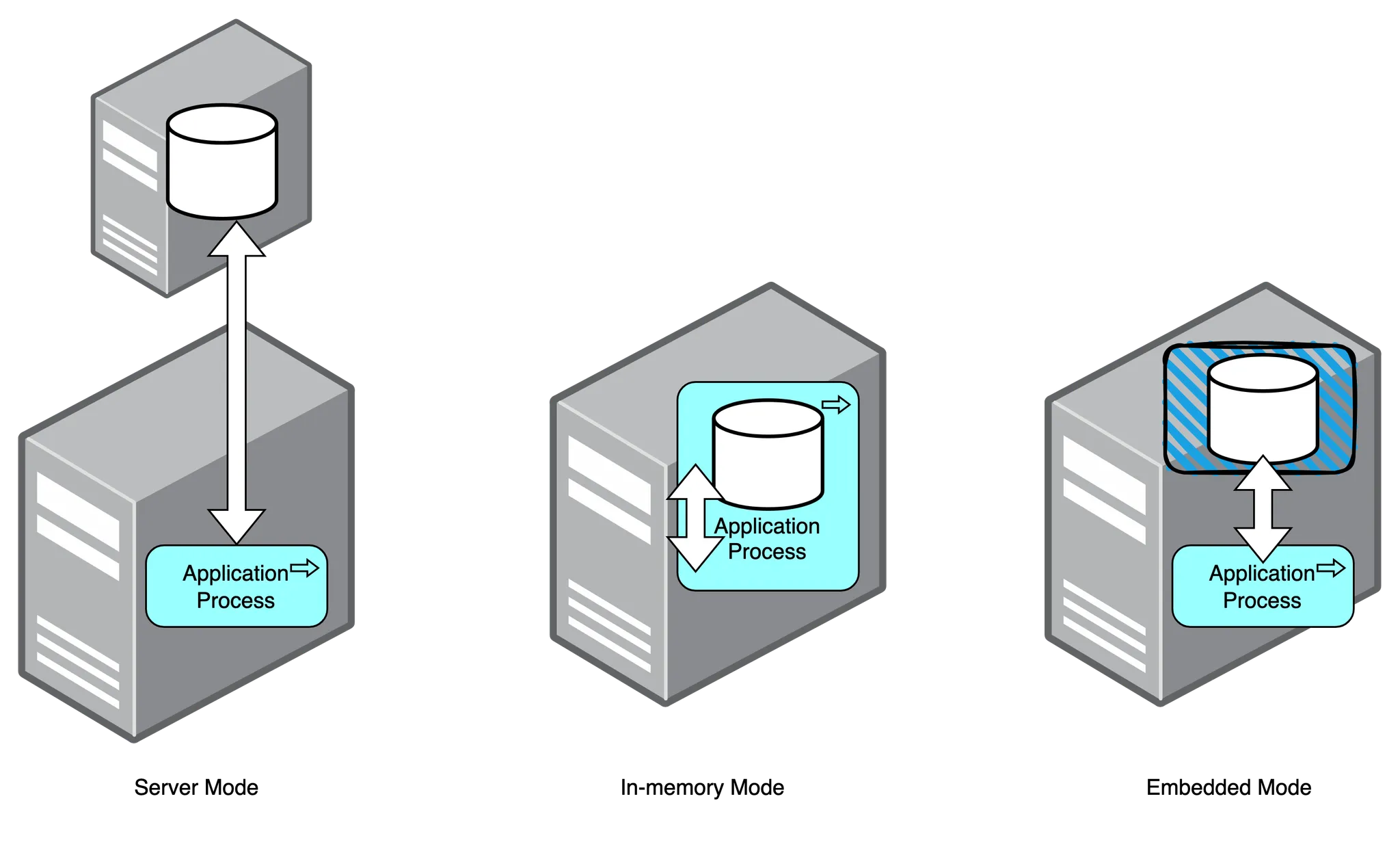
1) Server Mode
- 직접 엔진을 설치하여 사용하는 방식(현업에서 주로 사용)
- 애플리케이션과 상관 없는 외부에서 DB 엔진이 구동된다. -> 여러 애플리케이션에서 동일한 DB를 사용하기에 적합
- 데이터가 애플리케이션 외부에 저장되므로 애플리케이션을 종료해도 데이터가 사라지지 않는다.
2) In-memory Mode
- 엔진을 설치하지 않고 애플리케이션 내부의 엔진을 사용하는 방식.
- 애플리케이션을 실행하면 DB 엔진이 함께 실행되고 애플리케이션을 종료하면 DB 엔진이 함께 종료된다. -> 휘발성: 데이터가 애플리케이션의 메모리에 저장되기 때문에 애플리케이션이 종료되면 모든 데이터가 사라짐(단위 테스트)
- 데이터가 애플리케이션의 메모리에 저장되기 때문에 애플리케이션을 종료하면 데이터가 사라진다.
- build.gradle 및 application.properties 설정을 통해 실행 가능하다.
(mem을 url에 작성)
# application.yml
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:mem:{DB 이름}
username: sa
password:
# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:mem:{DB 이름}
spring.datasource.username=sa
spring.datasource.password=
3) Embedded Mode
- 엔진을 설치하지 않고 애플리케이션 내부의 엔진을 사용하는 방식.
- 애플리케이션을 실행하면 DB 엔진이 함께 실행되고 애플리케이션을 종료하면 DB 엔진이 함께 종료된다. (In-memory mode 특징)
- 데이터가 애플리케이션 외부에 저장되므로 애플리케이션을 종료해도 데이터가 사라지지 않는다. (Server mode 특징)
(url에 데이터가 저장될 경로 설정)
# application.yml
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:{DB가 저장될 경로}
username: sa
password:
# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:{DB가 저장될 경로}
spring.datasource.username=sa
spring.datasource.password=
| Mode | H2 다운로드 여부 | 실행 주체 | DB 저장 위치 | 사용 용도 |
| Server Mode | O | 외부 | 로컬(파일 시스템) | 배포 용도 |
| In-Memory Mode | X | 스프링 | 메모리 | 테스트 용도 |
| Embedded Mode | X | 스프링 | 로컬(파일 시스템) | 개발 용도 |
4. 데이터베이스 Driver
1) 데이터베이스 Driver 역할 및 종류
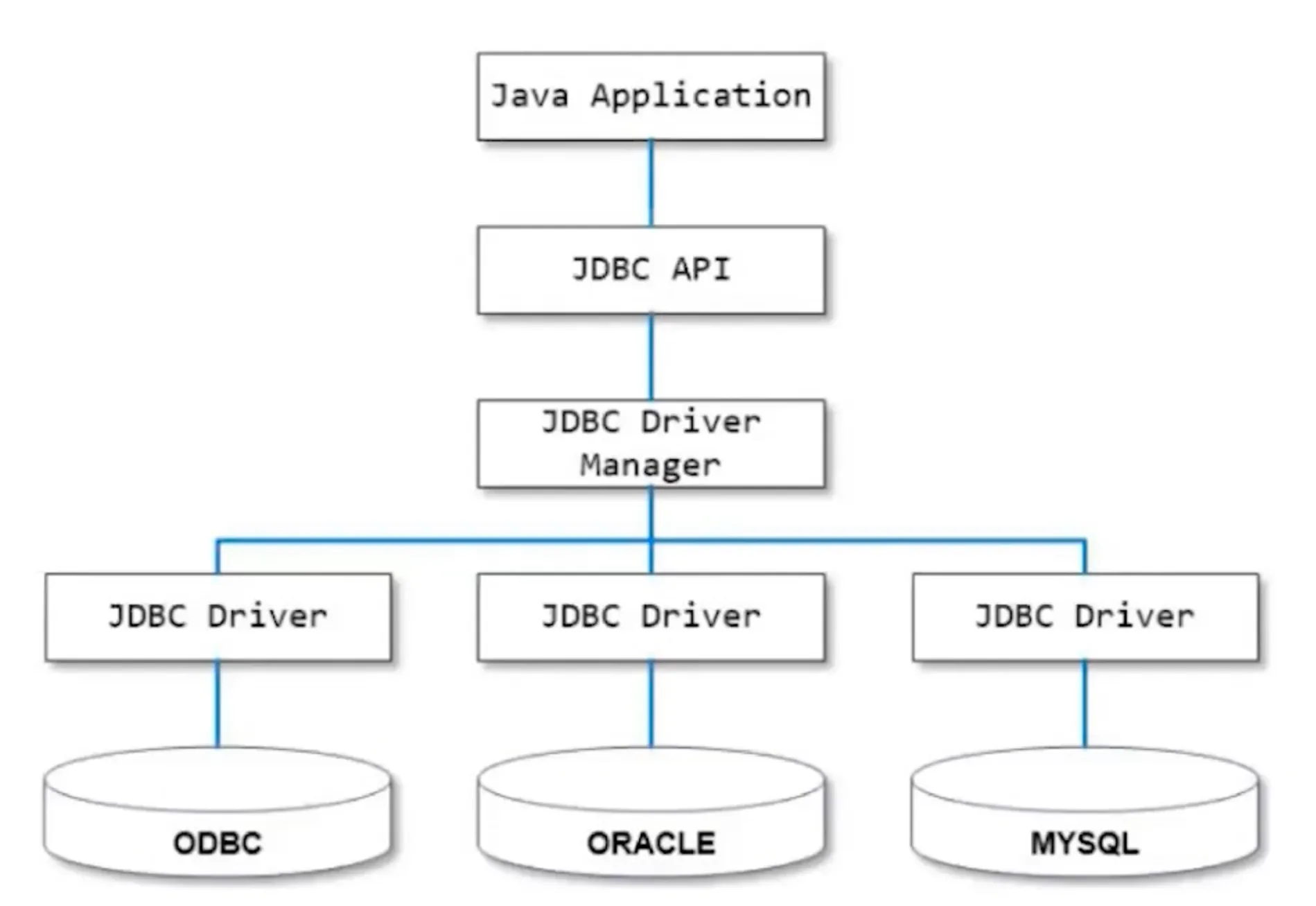
- 드라이버의 역할: 데이터베이스 드라이버는 애플리케이션과 데이터베이스 간의 통신을 중개하는 역할을 합니다. 마치 우체부가 편지를 전달하는 것처럼, 드라이버는 애플리케이션의 요청을 데이터베이스가 이해할 수 있는 언어로 변환
- 드라이버의 종류: 다양한 데이터베이스 시스템마다 호환되는 드라이버가 있습니다. 예를 들어, Oracle, MySQL, PostgreSQL 등 각 데이터베이스 제품에 맞는 특정 드라이버가 필요
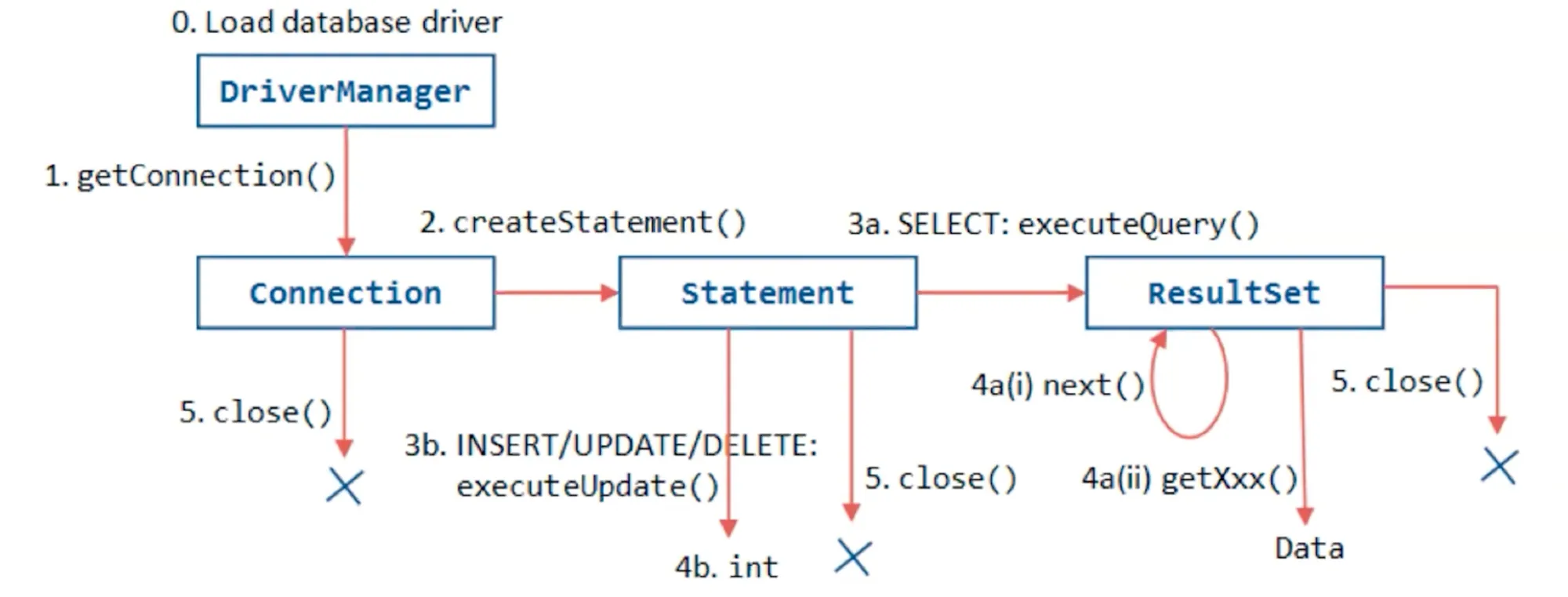
2) 데이터베이스 Driver 동작
1️⃣ 연결 초기화
- 요청 수신: 애플리케이션은 데이터베이스 작업을 시작하기 위해 드라이버에 연결을 요청
- 연결 설정: 드라이버는 데이터베이스 서버에 로그인하고 필요한 설정을 수행하여 연결을 완료합니다. 이 과정은 네트워크 정보, 인증 자격 증명 등을 사용하여 이루어짐.
2️⃣ SQL 전송 및 실행
- SQL 명령 변환: 애플리케이션에서 발송된 SQL 명령을 받은 드라이버는 해당 명령을 데이터베이스가 이해할 수 있는 형태로 변환.
- 명령 처리: 변환된 명령은 데이터베이스 서버로 전송되어 실행. 데이터베이스는 쿼리를 처리하고, 요구된 데이터를 검색하거나 데이터에 변화.
3️⃣ 결과 처리
- 결과 수신: 데이터베이스에서 작업의 결과를 보내면, 드라이버는 이 결과를 받아 애플리케이션에서 해석할 수 있는 형태로 변환.
- 결과 전달: 최종적으로, 드라이버는 이 결과를 애플리케이션에 전달. 애플리케이션은 이 정보를 사용자에게 표시하거나 다음 작업을 진행.
4️⃣ 연결 종료
- 연결 해제: 작업이 완료되면, 드라이버는 데이터베이스 서버와의 연결을 종료. 자원을 정리하고 다음 세션을 위해 시스템을 초기화합니다.